
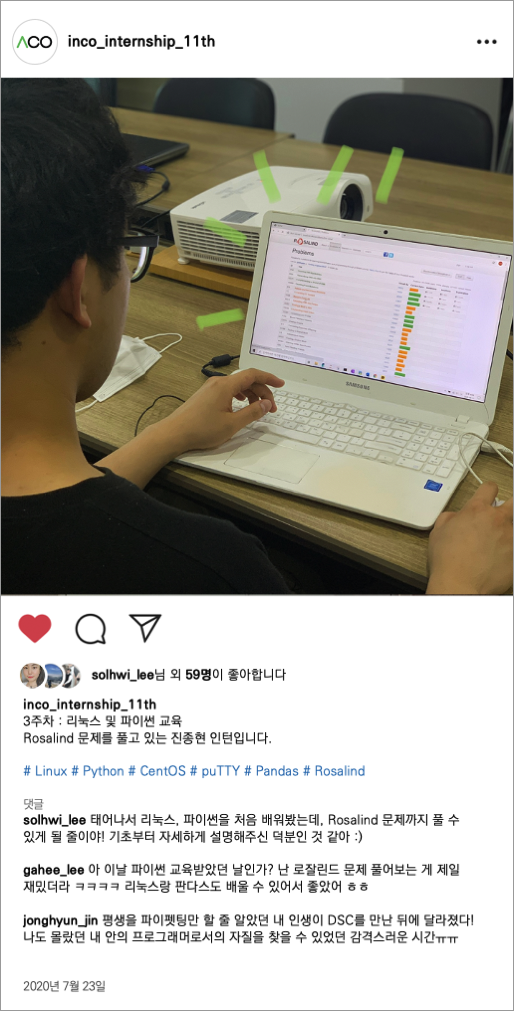
병원에 가지 않아도 나의 건강을 진단하고 치료한다?! - 라이프로그와 헬스케어
- Posted at 2021/07/08 16:02
- Filed under 정보공유

우리는 보통 "질병에 걸릴 것 같아서"가 아니라, 질병에 걸려 "발생하는 증상" 때문에 병원을 찾아 치료받곤 합니다. 따라서 증상이 늦게 발현되는 경우 혹은 증상을 알아채지 못한 경우, 치료 시기를 놓쳐 치료에 어려움을 겪거나 질병이 급격히 진행되는 일들이 자주 발생합니다.
또한, 만성 질환을 앓고 있거나 특정 치료법을 시행한 경우에는 환자가 입원하거나 매일 병원에 방문하지 못한다면, 자신의 건강 상태를 확인하고 예후를 지속해서 살펴야 하는 번거로움이 있습니다. 지금부터 소개할 "라이프로그" 데이터는 앞선 문제와 번거로움을 해소하는 데에 많은 도움을 주고 있습니다!

[그림 1] https://www.galendata.com/digital-healthcare-future-heathcare/

라이프로그란?
먼저 라이프로그(Life log)란 일상생활을 의미하는 'life'와 기록을 의미하는 'log'의 합성어이며, 문자 그대로 일상에서 기록 및 저장되는 모든 정보를 의미합니다. SNS에 업로드한 글, 일상적인 대화가 담긴 음성 파일 등 디지털로 기록 가능한 모든 데이터는 라이프로그라 할 수 있습니다.
특히, 헬스케어 분야에서 말하는 라이프로그는 병원에 방문하지 않고도 환자의 건강 상태를 실시간으로 업데이트하거나, 질환의 예후를 감지 및 예측하는 중요한 자료로 사용될 수 있는 PGHD(patient generated health data)의 확장된 범주로 분류되고 있습니다. PGHD는 데이터를 생성하는 주체가 질환을 앓고 있는 환자였다면, 라이프로그는 그 주체를 건강한 사람까지 포괄하는 개념입니다.
라이프로그의 등장
라이프로그는 자료를 저장하는 저장 장치와 데이터의 수집을 위한 센서가 더욱 정밀하게 발달하며, 그 양이 기하급수적으로 증가하기 시작하였습니다. 또한, IT 기술이 발전하고 정보와 지식을 공유하는 문화가 사회 전반에 자리매김함에 따라 더 많은 사람에 의해 다양한 종류의 라이프로그가 생산되고 있습니다.
라이프로그의 종류
라이프로그는 문자 그대로 일상에서 기록되는 모든 정보이기에, 그 종류가 정해져 있지는 않습니다. 모바일 기기의 사용 패턴부터 SNS 활동 로그까지 모든 개인의 삶에 대한 모든 데이터가 포함됩니다. 그 중 헬스케어 분야에서 자주 활용되는 라이프로그에는 크게 활동량 데이터, 영양 데이터, 자가 측정 임상 데이터, 커뮤니케이션 데이터 4가지가 존재합니다. 활동량 데이터는 라이프로그 중 가장 먼저 모이기 시작한 데이터이고, 웨어러블 디바이스를 통해 수동적인 방법으로 수집할 수 있습니다. 두 번째 영양 데이터는 활동량 데이터 다음으로 대두되고 있으며, 스마트폰에 직접 기입하는 형식으로 수집합니다. 식생활 변화를 헬스케어 분야에 적용할 수 있다는 장점이 있지만, 데이터의 형식이나 분석의 편차가 큰 편이라는 특징이 있습니다. 다음은 자가 측정 임상 데이터로 주로 환자를 대상으로 하며, 병원에서 측정해야 하는 임상 데이터를 환자가 수집할 수 있다는 장점이 있습니다. 그러나 사용자의 숙련도에 따라 정확도가 달라질 수 있다는 이슈가 있습니다. 마지막은 커뮤니케이션 데이터이며, 헬스케어 서비스 내 사용자의 대화 로그나 SNS 채널 내의 데이터 등이 포함됩니다. 위 4가지 카테고리 데이터는 현재도 많은 연구가 진행되고 있는 헬스케어 내의 라이프로그입니다. 이외에도 수많은 종류의 라이프로그가 존재하며 헬스케어 분야에 얼마든지 적용할 수 있기에 그 위상이 날로 증가하고 있습니다.
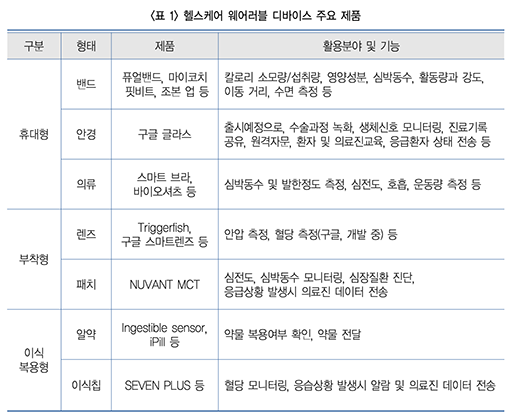
데이터의 종류의 따라, 사람이 주체적으로 데이터를 모바일이나 웹 애플리케이션에 직접 기입해야 하기도 하지만, 특별한 행위 없이도 디바이스에 의해 자동으로 데이터가 수집되기도 합니다. 예를 들어, 헬스케어에서 활동량 정보의 경우, <table.1 활동량 정보 예시: 헬스케어 웨어러블 디바이스 주요 제품>에서처럼 우리에게 익숙한 애플워치, 핏비트 등의 밴드형 기기 외에도 다양한 종류의 기기에 의해 자동으로 데이터가 모여 활용할 수 있는 형태로 반환됩니다. 웨어러블 디바이스에 의해 수집된 데이터는 이동 거리, 활동 강도 등의 비교적 간단한 정보부터 약물 복용 여부 등의 감지하기 어려운 데이터까지 포함되며, 이들은 의료진에게 직/간접적으로 전달하는 서비스를 통해 임상 데이터와 연동하여 체계적인 수술 후 건강 관리, 만성 질환의 관리 등에 활용될 수 있습니다.
라이프로그의 활용사례
[그림 4] https://dobrain.co](https://dobrain.co/
첫 번째 사례는 "두브레인"이라는 아이를 위한 두뇌 교육 모바일, 태블릿 애플리케이션입니다. 언뜻 보면 모바일 게임과 유사해 보이지만, 아동이 두뇌 게임을 하면 쌓이는 데이터들을 이용하여 장애 여부나 발달 수준을 진단하고, 진단 결과를 기반으로 발달 테라피나 인지 교육 프로그램을 제공하는 서비스입니다. 이 서비스는 국내 의과대학 연구진들과 함께 두뇌 게임의 플레이 데이터를 라이프로그 데이터로 활용하여 발달 장애를 진단하는 알고리즘을 개발하였다고 합니다.
첫 번째 사례는 "두브레인"이라는 아이를 위한 두뇌 교육 모바일, 태블릿 애플리케이션입니다. 언뜻 보면 모바일 게임과 유사해 보이지만, 아동이 두뇌 게임을 하면 쌓이는 데이터들을 이용하여 장애 여부나 발달 수준을 진단하고, 진단 결과를 기반으로 발달 테라피나 인지 교육 프로그램을 제공하는 서비스입니다. 이 서비스는 국내 의과대학 연구진들과 함께 두뇌 게임의 플레이 데이터를 라이프로그 데이터로 활용하여 발달 장애를 진단하는 알고리즘을 개발하였다고 합니다.
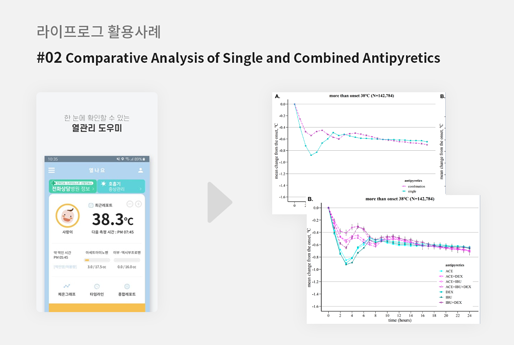
두 번째 사례는 아이의 체온을 관리해주는 "fevercoach"라는 모바일 애플리케이션에서 생성된 라이프로그 데이터를 활용한 연구 사례입니다. fevercoach 애플리케이션은 현재의 체온을 입력하면 아이가 어떤 상태이고, 어떤 행동을 취하면 좋은지를 제시해줍니다. 또한, 이 서비스에는 아이가 접종받은 백신의 종류와 열이 났을 때 어떤 해열제를 얼마만큼 복용하였는지를 기입할 수 있습니다. 이와 같은 아이의 기초 정보와 체온 변화 정보, 해열제 종류 및 복용량 정보는 라이프로그 데이터로 축적되어 해열제의 단일 복용과 복합 복용에 따른 체온 조절 효과를 연구하는 데에 기여한 바가 있습니다.
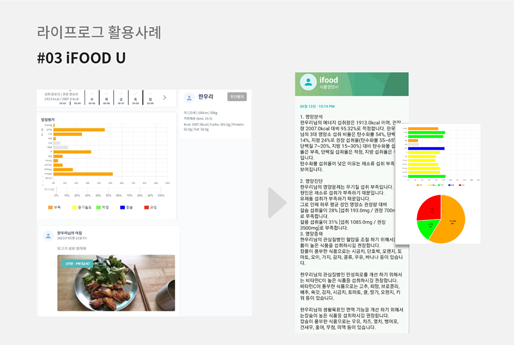
[그림 6] https://d-if.kr/ifood_gene/
세 번째 사례는 라이프로그 데이터 중 섭취음식 사진 데이터를 활용하여 비대면 영양관리 해주는 iFOOD-U 모바일 애플리케이션 서비스입니다. iFOOD-U는 매 끼니를 모바일 기기를 통해 촬영한 영상에서 각 식품을 인식하고, 식품별 영양 성분을 분석하여 영양 데이터를 생성합니다. 이 영양 데이터는 전문 영양사에게 전달되어, 고객의 식이 섭취행태를 파악하고, 이를 기반으로 레포트 형태의 더 나은 섭취 방안을 제시하는 근거 자료로 활용되고 있습니다.
라이프로그의 한계와 도전
라이프로그는 데이터를 생성하는 대상에 제한이 적고, 데이터의 수집이 비교적 간편합니다. 또 주로 개인이 수집하는 데이터이기에, 병원에 축적된 임상 데이터 혹은 유전체 데이터와 연계한다면, 그 활용 범위는 무한에 가깝다 해도 과언이 아닙니다. 그러나 라이프로그를 다른 원천 데이터와 연동하여 활용하는 것이 그리 쉬운 일은 아닙니다. 라이프로그는 개인이 생성하는 반면, 전자 의무 기록이나 임상 데이터들은 환자 혹은 개인이 방문하였던 여러 의료 기관에 산재하여 있기 때문입니다. 또한, 의료기관마다 사용하는 전자 의무 기록의 형식이 조금씩 다르기에 개인의 정보와 직접 연동하기 위해서는 데이터를 통합하고 정리하기 위해 많은 시간이 필요합니다.
덧붙여, 라이프로그는 다른 데이터와는 다르게 특정 기관에서 생성하는 데이터가 아니라, 다양한 방식으로 여러 사람이 생성하는 데이터입니다. 따라서 데이터의 소유권이 누구에게 있는지, 데이터를 활용하려면 데이터 제공에 따른 대가를 어떤 방식으로 산정해야 하는지 등의 데이터의 권리에 대한 이슈가 불거지고 있습니다. 권리뿐만 아니라 개인의 일상생활과 관련한 데이터이기에 사생활 침해나 가명처리와도 밀접하게 관련되어 있습니다. 다행히, 공공 기관에서도 데이터 3법과 같이 피해를 최소화하며 기술의 발전은 최대화하도록 법을 개정하고 규율을 정하기 위해 노력하고 있어, 데이터 관련 이슈는 계속해서 개선될 것으로 보입니다.
마치며
덧붙여, 라이프로그는 다른 데이터와는 다르게 특정 기관에서 생성하는 데이터가 아니라, 다양한 방식으로 여러 사람이 생성하는 데이터입니다. 따라서 데이터의 소유권이 누구에게 있는지, 데이터를 활용하려면 데이터 제공에 따른 대가를 어떤 방식으로 산정해야 하는지 등의 데이터의 권리에 대한 이슈가 불거지고 있습니다. 권리뿐만 아니라 개인의 일상생활과 관련한 데이터이기에 사생활 침해나 가명처리와도 밀접하게 관련되어 있습니다. 다행히, 공공 기관에서도 데이터 3법과 같이 피해를 최소화하며 기술의 발전은 최대화하도록 법을 개정하고 규율을 정하기 위해 노력하고 있어, 데이터 관련 이슈는 계속해서 개선될 것으로 보입니다.
마치며
우리가 이 글을 읽는 와중에도, 작은 규모의 로그 데이터들은 계속해서 생성되고 있습니다. 이는 하찮고 용량만 차지하는 데이터로 취급될 수도 있지만, 누군가에게는 우리의 삶을 더 풍요롭게 만드는 가치 있는 자원으로 여겨지기도 합니다. 우리도 이번 기회로 라이프로그의 잠재력을 알았으니, 지금부터 라이프로그 데이터의 또 다른 의미를 찾아보면 어떨까요?
참고자료
참고자료
- Bang C, Nam Y, Ko EJ, Lee W, Kim B, Choi Y, Park YR. A serious game-derived index for detecting children with heterogeneous developmental disabilities: A randomized clinical trial. JMIR Preprints. 04/06/2019:14924
- Park Y, Kim H, Park J, Ahn S, Chang S, Shin J, Kim M, Lee J. Comparative Analysis of Single and Combined Antipyretics Using Patient-Generated Health Data: Retrospective Observational Study. JMIR Mhealth Uhealth 2021;9(5):e21668
- https://crcaustralia.com/media-releases/real-world-data/
작성 : AIDX 이주연 개발자
Posted by 人Co
- Tag
- healthcare, insilicogen, lifelog, 라이프로그, 비대면진료, 셀프진단, 웨어러블, 인실리코젠, 헬스케어
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/387













































 [그림 8]
[그림 8] 





