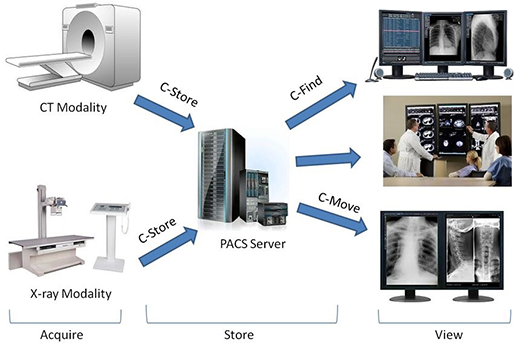
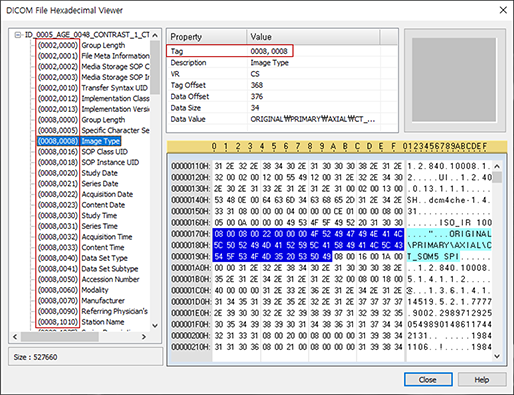
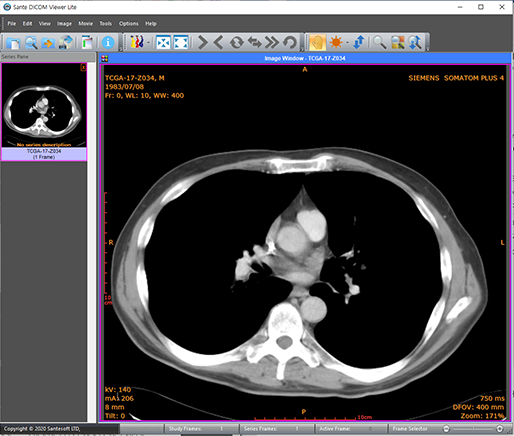
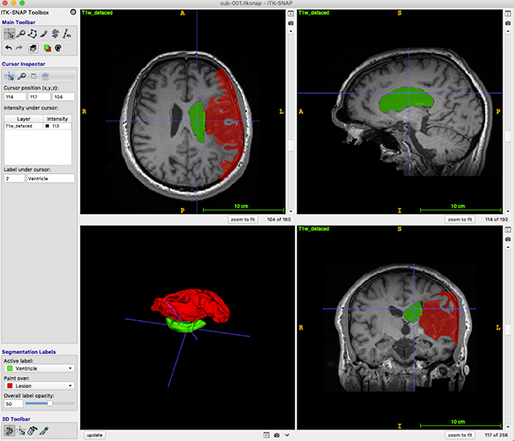
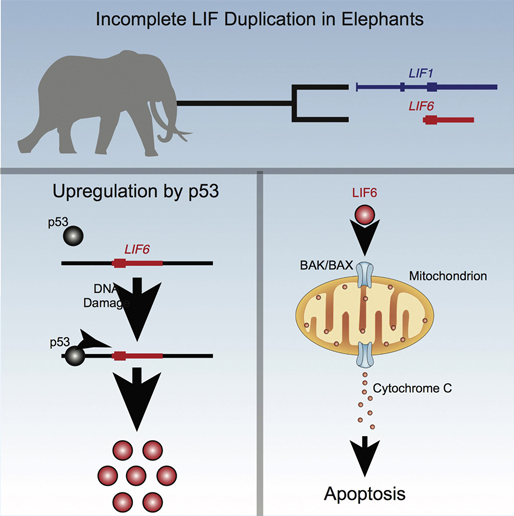
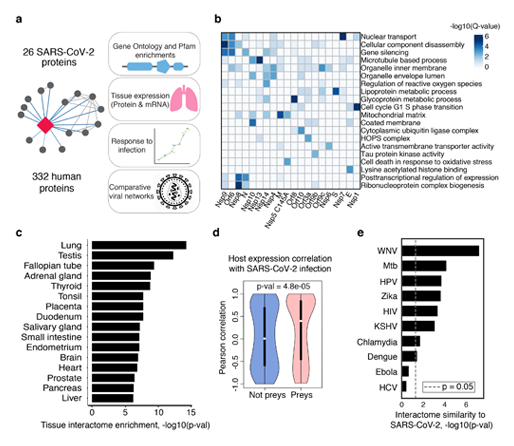
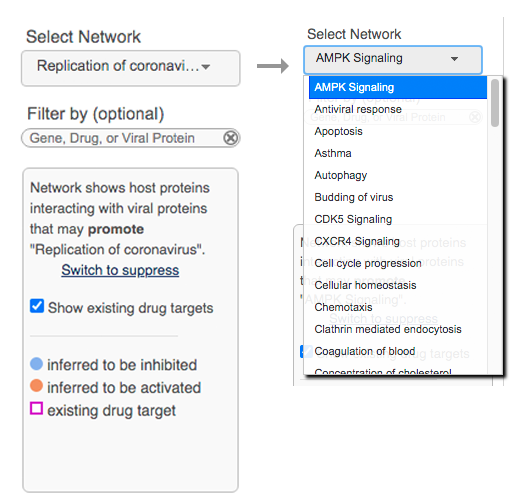
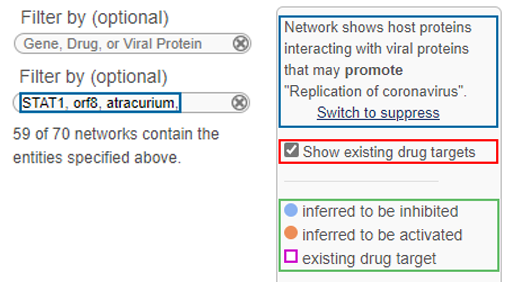
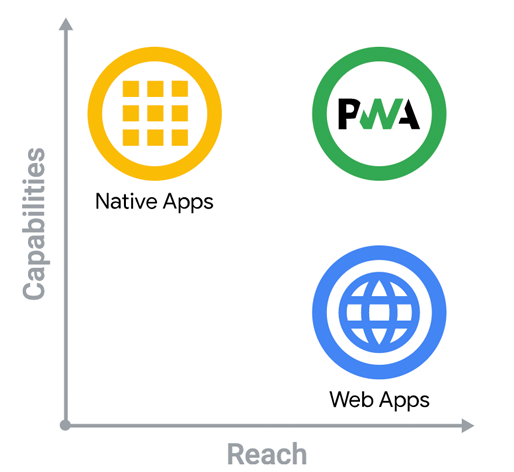
모바일 중심시대! 개발자의 위치는? - 앱 개발편
- Posted at 2021/07/25 22:53
- Filed under 지식관리

"2020년까지 전 세계 인구의 절반 이상이 인터넷에 연결될 것입니다."라는 말이 나오기 무섭게 2021년 지금은 인구의 절반을 넘어선 대다수가 인터넷에 연결이 되었습니다. 이에 앞서 MZ세대는 단순 인터넷이 아닌 모바일을 중심으로 사용하고 있습니다. 실제로 인터넷 사용자 4명 중 1명 이상이 이미 모바일 중심 사용자에 해당합니다.
[그림 1] "Mobile Only"

[그림 2] "Mobile Users by Country"
이처럼 현대 시장은 모바일에서 돌아간다고 할 수 있을 정도로 모바일의 중요성이 커지는 시점이 되었습니다.
예로 A 씨의 휴일 일상을 들여다보겠습니다.
이처럼 현대 시장은 모바일에서 돌아간다고 할 수 있을 정도로 모바일의 중요성이 커지는 시점이 되었습니다.
예로 A 씨의 휴일 일상을 들여다보겠습니다.
오전
-08시 : 일어나자마자 카톡, 페이스북, 인스타그램 확인
-10시 30분 : 네이버, 다음 뉴스 보고 동영상 검색
오후
-13시 : 밥을 먹으며 유튜브 콘텐츠 감상
-14시 : 의류 직구 카페에 올라온 상품이 혹해서 인스타그램, 페이스북, 블로그 후기를 찾아봄(후기가 별로라서 구매하지 않음)
-16시 : 네이버 쇼핑을 보다가 가격이 너무 괜찮은 바지 N-페이로 구매(적립금 2,000원 사용)
-17시 : 항상 들어가 있는 커뮤니티 사이트 배너에서 `여행` 배너를 보고 호기심에 클릭
-18시 : 배달 앱을 이용해 저녁 메뉴 배달 주문 및 식사
-20시 : 여행 배너에 혹해서 네이버 톡톡으로 호텔 숙박 가격 문의
-24시~ 새벽 01시 : 카페에서 해당 호텔 및 관광 후기에 대해 찾고 또 찾아보다 잠이 듦
*깨어있는 내내 카카오톡,SNS(페이스북,인스타그램, 블로그,카페 사용)
*음악, 카메라, 배달 애플리케이션 사용
위에 일과를 보면 아침에 눈을 떠서부터 감을 때까지 스마트폰을 놓지 않는 것을 볼 수 있습니다. 이처럼 모바일을 주된 매체로 쓰는 요즘 시대에 여러분은 모바일에 대해서 얼마나 알고 계신가요?? 이번 포스팅에서는 모바일에 관한 내용 중 모바일 앱 개발에 관해서 말씀을 드리겠습니다.
모바일 앱 개발은 스마트폰의 애플리케이션을 개발하는 것을 말합니다. 모바일 온리(Mobile Only) 시대가 오면서 스마트폰의 사용성이 많이 올라가고, 여러 기업에서 스마트폰으로 서비스를 하는 경우가 많아졌습니다. 인실리코젠도 역시 스마트폰을 이용한 분석 및 서비스를 하고 있으며 크게 ‘헬스케어’와 ‘데이터 분석’ 두 가지 카테고리로 나눠 소개하겠습니다.
모바일 앱 실제 활용 사례 - 인실리코젠, 디이프
- 활용 사례 #01 헬스케어
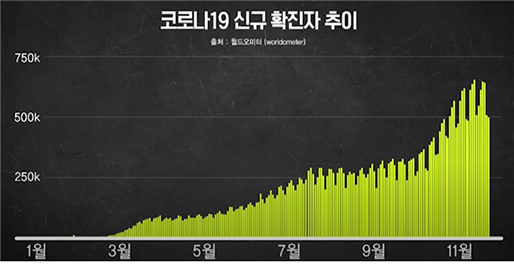
건강이라는 용어는 임상 및 비임상 모집단 모두에서 다양한 의료 활동을 설명하는 데 사용할 수 있습니다. 예를 들어, 수천 개의 인기 있는 스마트폰 앱을 건강 카테고리에서 다운로드하여 개인이 체력을 향상시키고 칼로리를 계산하며 수면을 모니터링할 수 있습니다. ‘라이프로그데이터’ 포스팅(https://insilicogen.com/blog/387) 에서 언급했던 바와 같이, 병원을 가지 않고 혼자서 헬스케어를 할 수 있는 시대가 되었습니다. 게다가 코로나가 심각해지면서 외출을 하기 꺼려지고, 병원을 가는 것조차 무서워지고 있는 상황에서는 이처럼 개인의 건강을 집에서 확인할 수 있는 기술이 무척 중요해졌습니다.

[그림 3] "digital_healthcare_future"
(https://www.galendata.com/digital-healthcare-future-heathcare/)

(https://www.galendata.com/digital-healthcare-future-heathcare/)
개인의 건강을 집에서 확인하기 위해서는 검진을 할 수 있는 키트와 검사 결과를 볼 수 있는 매체가 필요합니다. 대표적으로 코로나 검사의 경우 코로나 검사 키트가 있을 수 있고, 유전자 검사를 하기 위한 DTC 유전자 검사 키트가 있습니다.
[그림 4] 좌 : corona test kit, 우 : "dtc dna test kit"
검사를 하고 검사 결과를 메일 혹은 우편으로 받아 볼 수 있으며, 이러한 결과를 편리하게 분석하기 위한 다양한 모바일 서비스가 있습니다.
일반인의 경우 검사 결과 통지서를 보고 결과가 어떻게 나왔는지 한눈에 알기는 쉽지 않습니다. 이 때문에 여러 서비스에서 이러한 결과를 보기 좋게 분석하고 표현해줍니다. 이럴 때 필요한 것이 모바일 앱입니다.
검사 결과를 모바일 앱을 통해 편리하게 제공하고, 이에 따른 헬스케어를 할 수 있도록 서비스를 제공하는 역할을 하게 됩니다. 모바일 앱 개발자는 이러한 서비스를 만들기 위해 검사 결과를 분석하는 데이터 분석가와 함께 서비스를 기획하고, 사용자가 더욱 편리하게 검사 결과를 이용할 수 있도록 앱을 개발하게 됩니다. 이러한 개발은 지속적인 서비스로 제공되어야 합니다. 따라서 시기에 맞는 적절한 서비스 기획 및 개발로 꾸준하고 지속적인 업데이트가 중요합니다.
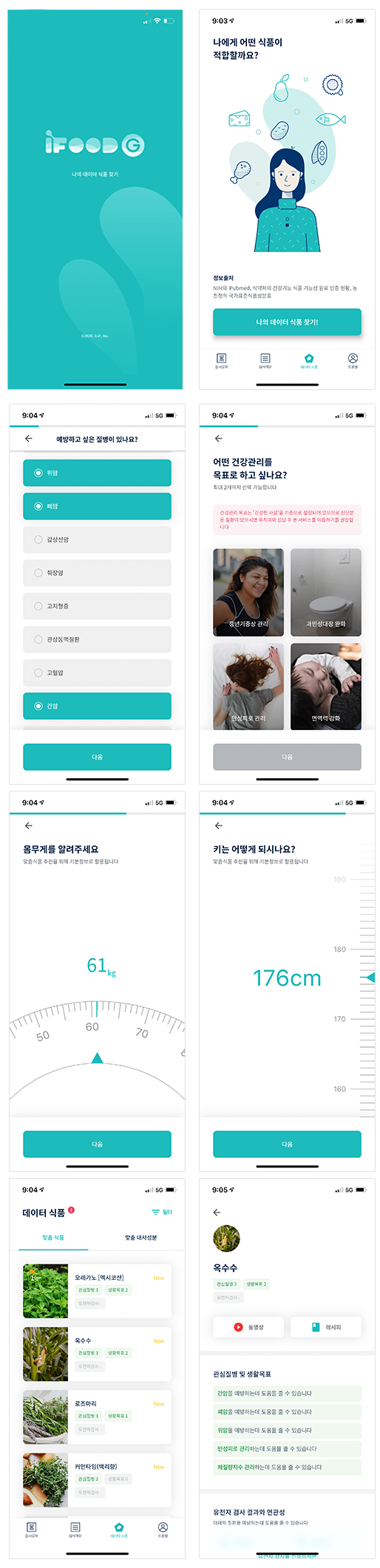
일반인의 경우 검사 결과 통지서를 보고 결과가 어떻게 나왔는지 한눈에 알기는 쉽지 않습니다. 이 때문에 여러 서비스에서 이러한 결과를 보기 좋게 분석하고 표현해줍니다. 이럴 때 필요한 것이 모바일 앱입니다.
검사 결과를 모바일 앱을 통해 편리하게 제공하고, 이에 따른 헬스케어를 할 수 있도록 서비스를 제공하는 역할을 하게 됩니다. 모바일 앱 개발자는 이러한 서비스를 만들기 위해 검사 결과를 분석하는 데이터 분석가와 함께 서비스를 기획하고, 사용자가 더욱 편리하게 검사 결과를 이용할 수 있도록 앱을 개발하게 됩니다. 이러한 개발은 지속적인 서비스로 제공되어야 합니다. 따라서 시기에 맞는 적절한 서비스 기획 및 개발로 꾸준하고 지속적인 업데이트가 중요합니다.
[그림 5] 디이프의 'iFood Gene' - 유전자 맞춤형 데이터 식품 추천 앱
(https://d-if.kr/ifood_gene/)
(https://d-if.kr/ifood_gene/)
- 활용 사례 #02 데이터 분석
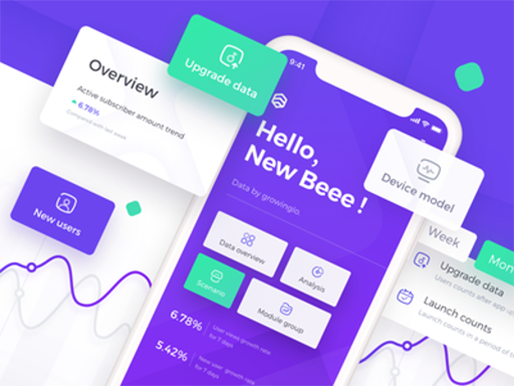
[그림 6] mobile analytics
(https://dribbble.com/shots/4001028-Design-Of-Data-Analysis-App)
(https://dribbble.com/shots/4001028-Design-Of-Data-Analysis-App)
특정 기관에서 소고기의 등급을 판정하는 방법의 개선을 찾는 도중에, 주관적인 의견이 들어가지 않고, 기계를 이용해 객관적인 판정을 내리는 방법을 모색했습니다. 소고기의 등급을 판정하기 위해서는 특정 부위의 고기를 보고 여러 지표를 통해 등급을 판정하는 방식인데, 이를 기계로 처리하기 위해서는 해당 고기를 촬영할 수 있고, 정해진 규칙에 따라 등급을 판정해야 합니다. 이때 스마트폰의 카메라 기능과 CPU, GPU를 이용하면 효율적으로 분석을 할 수 있다는 것을 알게 되었습니다.
스마트폰 카메라로 소도체를 촬영하고, Image Processing, Deep learning 기술을 이용하여 지표를 분석하는 등급 판정 애플리케이션을 개발하면서 소고기의 등급 판정을 스마트폰으로 할 수 있게 되었습니다.
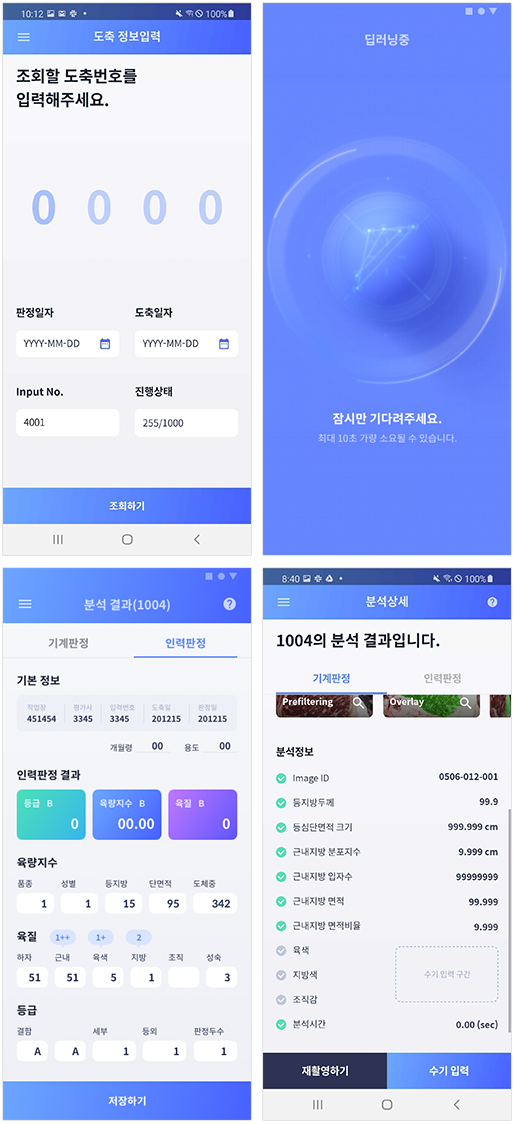
스마트폰 카메라로 소도체를 촬영하고, Image Processing, Deep learning 기술을 이용하여 지표를 분석하는 등급 판정 애플리케이션을 개발하면서 소고기의 등급 판정을 스마트폰으로 할 수 있게 되었습니다.
[그림 7] 인실리코젠의 'Cow Scan'
마치며
이처럼 일반적인 개발 분야에서만이 아닌 다양한 분야에서 데스크톱 및 모바일용 프로그램이 많이 사용되면서 이에 따른 개발의 수요도 많아지고 있습니다. 이번 포스팅에는 생물 정보에 기반한 모바일 프로그램에 관해서 설명하면서 시대가 변해가며 고객들의 편의성을 확보하기 위한 무궁한 기술 발전이 있음을 소개했습니다.
모바일 온리 시대에서는 모든 작업을 모바일로 할 수 있는 시대를 바라보고 있으며 일명 융합 소프트웨어를 이용한 시대 구축에 힘을 쏟게 될 것입니다. 지금부터 스마트폰을 사용만 하기보다는 한발 앞서나가 개발에 관심을 가져보는 것은 어떨까요? 그리고, 꼭 IT 전문기업이 아니더라도 생물 정보 전문기업 인실리코젠처럼 4차산업혁명 시대에 유망하고 비전 있는 분야에 합류하여 기술과 산업을 이끌어간다면 보다 큰 의미를 찾을 수 있을 것입니다!
모바일 온리 시대에서는 모든 작업을 모바일로 할 수 있는 시대를 바라보고 있으며 일명 융합 소프트웨어를 이용한 시대 구축에 힘을 쏟게 될 것입니다. 지금부터 스마트폰을 사용만 하기보다는 한발 앞서나가 개발에 관심을 가져보는 것은 어떨까요? 그리고, 꼭 IT 전문기업이 아니더라도 생물 정보 전문기업 인실리코젠처럼 4차산업혁명 시대에 유망하고 비전 있는 분야에 합류하여 기술과 산업을 이끌어간다면 보다 큰 의미를 찾을 수 있을 것입니다!
참고자료
- Mobile Data Science and Intelligent Apps: Concepts, AI-Based Modeling and Research Directions - Iqbal H. Sarker
- Mobile Data Science: Towards Understanding Data-Driven Intelligent Mobile Applications - Iqbal Sarker
-
https://www.facebook.com/business/news/insights/shifts-for-2020-mobile-command-center
작성 : AIDX 이채민 개발자
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/389








 [Fig. 1] 전주한정식
[Fig. 1] 전주한정식