웹 기술로 앱을 만들다! 프로그레시브 웹 앱스(Progressive Web Apps)
- Posted at 2020/07/04 18:42
- Filed under 지식관리

오늘 블로그 주제는 과거 2016년 구글 Google I/O 에서 소개된 웹 기술 프로그레시브 웹앱(Progressive Web Apps)을 다루어 보고자 합니다.
구글에서는 프로그레시브 웹앱(이하 PWA)을 최고의 웹과 최고의 앱을 결합한 경험으로 정의하고 있는데요, 브라우저를 처음 방문하는 사용자에게 유용하며, 별도의 설치를 요구하지 않습니다. 이러한 PWA라는 웹 기술이 탄생하게 된 배경과 자세한 내용을 차근차근 알아가 보도록 하겠습니다.

과학기술정보통신부에서 발표한 '2019년 인터넷이용실태조사' 결과를 보면, 우리나라 가구의 인터넷 접속률은 99.7%로 거의 모든 가구에서 인터넷을 접속하고, 접속 가구는 와이파이(100%), 모바일 인터넷(94.9%) 등 무선방식을 통해 주로 접속하는 것으로 나타났습니다.

[Flag.1] 2019년 인터넷이용실태조사 상세보기
2007년 아이폰이 처음 등장한 후 스마트기기 보급률은 급속히 증가했고 이동통신 기술의 발전으로 통신서비스의 중심이 데스크톱에서 모바일로 이동하는 등 2016년을 기점으로 모바일 시장 점유율이 데스크톱을 넘어서게 됐습니다. 데스크톱 뿐만 아니라 스마트폰, 태블릿, 심지어 TV에서도 웹에 접속할 수 있는 환경이 만들어짐으로써 언제 어디서나 정보로의 접근이 가능해졌습니다.
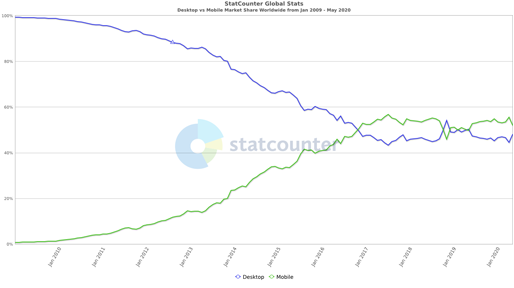
[Flg.2] Desktop vs Mobile Market Share Worldwide
웹(Web)에 접근할 수 있는 기기의 폭이 넓어진 만큼, 다양한 기기에 대응하기 위해 유연한 너비와 유연한 이미지, 미디어 쿼리를 이용해서 기기 사이즈에 맞추어 레이아웃을 재구성하는 반응형 웹(Responsive Web) 기술이 보편화하였습니다.
그러나 그림에서 보듯이 모바일 환경에서는 대부분의 사람이 웹(Web)보다는 앱(App)에서 더 많은 시간을 보낸다는 것을 알 수 있습니다. 모바일 환경에서 웹보다 앱을 더 선호하는 이유는 앱이 웹보다는 더 빠르고 편하며 사용성이 좋기 때문입니다.
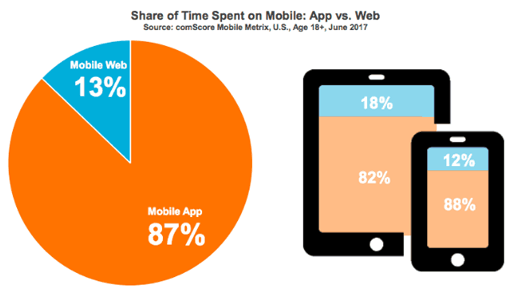
[Flg.3] Share of time spent on Mobile: App vs Web
(https://www.comscore.com/Insights/Presentations-and-Whitepapers/2017/The-2017-US-Mobile-App-Report)

2015년에 구글 크롬의 엔지니어 알렉스 러셀(Alex Russel)이 자신의 블로그에 'Progressive Web Apps: Escaping Tabs Without Losing Our Soul' 라는 제목의 글을 통해 차세대 웹의 개념, 즉 웹은 웹인데 점진적으로 앱 수준으로 근접해가는 웹이라는 개념의 아이디어를 제공했습니다. 그리고 이듬해 Google I/O(개발자 콘퍼런스) 2016에서 PWA를 미래의 웹 기술로 소개합니다.
비록 웹이지만 데스크톱이나 모바일에서 설치가 가능하고 앱과 유사한 사용자 환경을 제공해주며 하이브리드앱(Hybrid App)과 비교했을 때 보다 간편하게 설치와 개발을 할 수 있고 무엇보다 검색이 가능합니다. 앱과 유사한 경험을 지원하기 위해 푸쉬알림(Push Notification), 설치(Install), 오프라인 실행(Offline Access) 등의 기능도 지원합니다.
PWA에 대한 설명에서 가장 자주 등장하는 단어는 'App like'와 'Natively' 이지만 링크(URL)로 공유가 가능한 웹 페이지입니다. 즉, PWA는 다음 그림과 같이 앱(App)이 가지고 있는 높은 품질(Capability)과 웹(Web)의 넓은 도달 범위(Reach)를 결합한 개발 형태입니다.
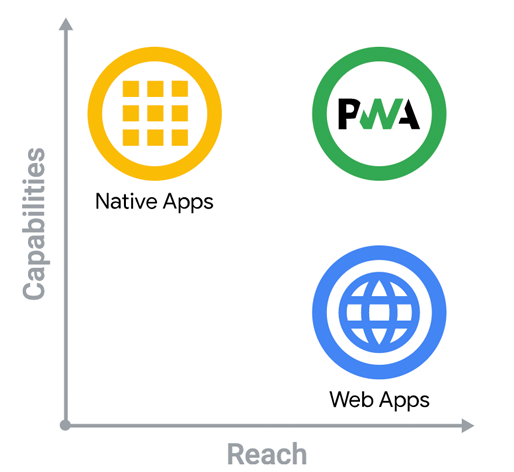
[Flg.4] 앱과 웹, 프로그레시브 웹의 기능 및 도달 범위,

- 반응형(Responsive) 기기에 따라 레이아웃을 자동으로 조정하는 등 다양한 플랫폼과 여러 기기에서 동일한 사용자 경험(UX)을 제공해줍니다.
- 연결 독립적(Reliable) 로컬 기기의 캐시를 활용하여 오프라인이나 불안한 네트워크에서도 실행할 수 있습니다.
- 재참여 가능(Engageble) 브라우저가 닫혀 있더라도 푸쉬 알람(Push Notification)을 보낼 수 있어서 재방문율을 높여줍니다.
- 안전성(Safe) HTTPS 통신으로 제공되므로 기존 웹 대비 안전합니다.
- 설치 가능한 경험 제공(Installable) 앱스토어를 찾지 않아도 브라우저에서 바로 빠르고 간단히 홈스크린에 앱을 둘 수 있습니다.
- 검색을 통해 발견 가능(Search) 구글, 네이버 등 포털 검색 결과에 노출됩니다.
- 링크 연결 가능 링크(URL)를 통해 손쉽게 공유할 수 있습니다.
- 즉각적인 업데이트
- 경량

- 로딩 속도와 성능이 다소 떨어집니다.
- 일부 플랫폼에 제한이 있습니다.
- 크롬, 오페라, 파이어폭스에서는 동작하지만, 사파리 브라우저에서 지원되지 않습니다.
- 아이폰에서 푸시알림을 보낼 수 없고 Siri와 통합할 수 없는 등 일부 기기에서 기본 기능에 제한이 있습니다.
- 지오 펜싱, 지문 스캐닝, NFC, Bluetooth 및 고급 카메라 기능과 같은 장치 기본 기능을 지원하지 못합니다.
- PWA를 사용하려면 인터넷에 액세스해야 하므로 배터리 수명을 더 빨리 소모합니다.

PWA는 최신 웹 기능을 활용합니다.
- 웹 메니페스트(Web App Manifest) 브라우저가 웹 앱을 설치할 때 그리고 홈 화면에서 웹 앱을 적절히 표현하는 데 필요한 정보 등을 담고 있습니다.
- 서비스 워커(Service Worker) 브라우저가 백그라운드에서 실행하는 스크립트로, 웹페이지와는 별개로 작동하며, 푸시 알림(Push Notification, Android Chrome 한정) 및 백그라운드 동기화(Background Sync, Android Chrome 한정)와 같은 기능 등 웹페이지 또는 사용자 상호작용이 필요하지 않은 기능에 대해 지원합니다.
- 반응형 웹(Responsive Web) 현재 사용되는 대부분의 반응형 웹 기술들을 사용합니다.

앱을 다운로드하지 않고 웹주소를 클릭해 앱과 유사한 서비스를 이용하게 해주는 PWA 장점을 살려 여행, 유통, 뉴스 분야에 활용도가 높을 것으로 보입니다. 핀터레스트(Pinterest), 알리바바(Alibaba), 트위터 라이트(Twitter Lite) 등 PWA 도입으로 접속 시간은 상승하고, 이탈률은 감소하는 등 유의미한 결과를 얻는 많은 사례를 볼 수 있습니다.
- 핀터레스트(Pinterest)
- 평균 접속 시간이 40% 증가하였고 사용자 생성 광고 수익이 44% 증가, 핵심 사용자 참여율이 60% 증가하였다고 보고하고 있습니다.
- 안드로이드 및 아이폰 앱과 비교하면 9.6MB 및 56MB에 비해 150KB로 매우 가볍습니다.
[Flag. 5] PWA Pinterest
- 그 외 PWA 도입 사례들
- http://progressivewebapproom.com
- (PWA examples) 2020 PWA 웹 앱의 12가지 대표 사이트, https://www.simicart.com/blog/progressive-web-apps-examples/
- PWA 도입 후 전환율 수치를 보여주는 웹 사이트

현재 구글을 주축으로 마이크로소프트(MS), 모질라(Mozilla), 오페라(Opera) 등이 동참하고 있고 대부분의 안드로이드 기기에서는 PWA를 완벽하게 지원하지만 아쉽게도 iOS 기기에서는 여전히 제한적입니다.
그럼에도 불구하고 우리나라에서도 대표적 쇼핑몰 플랫폼 CAFE24가 PWA를 적용한 '스마트웹 앱'을 출시하는 등 점점 많은 전자 상거래 사이트에 PWA를 적용해서 구현하고 있습니다. 이는 앱을 개발하는데 드는 비용 대비 비교적 적은 자원으로 높은 효율을 기대하는 것을 목표로 하는 전자 상거래 사이트에 대안이 될 수 있기 때문입니다.
(주)인실리코젠의 자회사인 (주)디이프 에서도 현재 서비스중인 아이푸드진 앱을 개발할 당시 여러 기술들 중 하나로 PWA도 함께 고려한 바 있습니다. 비록 네이티브 앱의 기능을 충분히 활용하고 호환성에서 높은 점수를 얻은 플러터(Flutter)가 채택되었지만, 사용자 친화적인 앱을 만드는데 이제 더 이상 웹 기술을 포기할 필요가 없어졌습니다. PWA가 아직 완벽하지 않지만, iOS나 안드로이드 같은 플랫폼 전용 폐쇄적인 앱에 비해 유연하고 개방적이어서 플랫폼에 종속되지 않는 웹의 특성으로 볼 때 PWA의 더 큰 성장을 기대해봅니다.

-
구글 개발자 블로그, https://web.dev/progressive-web-apps/
-
글로벌 모바일 소매 상거래 판매 점유율(2016 ~ 2021), https://www.statista.com/statistics/806336/mobile-retail-commerce-share-worldwide/
작성 : FED 팀 김태영 선임 개발자
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/350




 人CoINTERNSHIP_지원서_2020.doc
人CoINTERNSHIP_지원서_2020.doc






 [그림 8]
[그림 8] 









 [그림 3]
[그림 3]