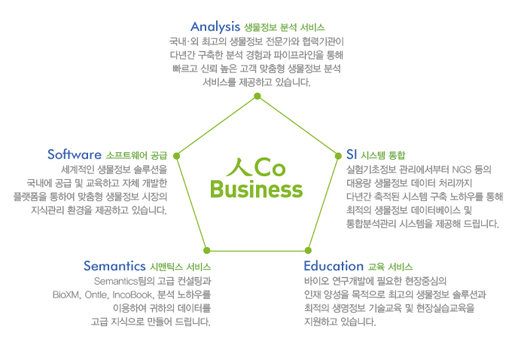
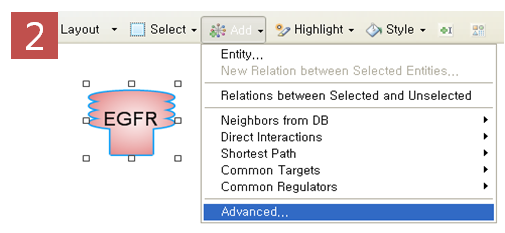
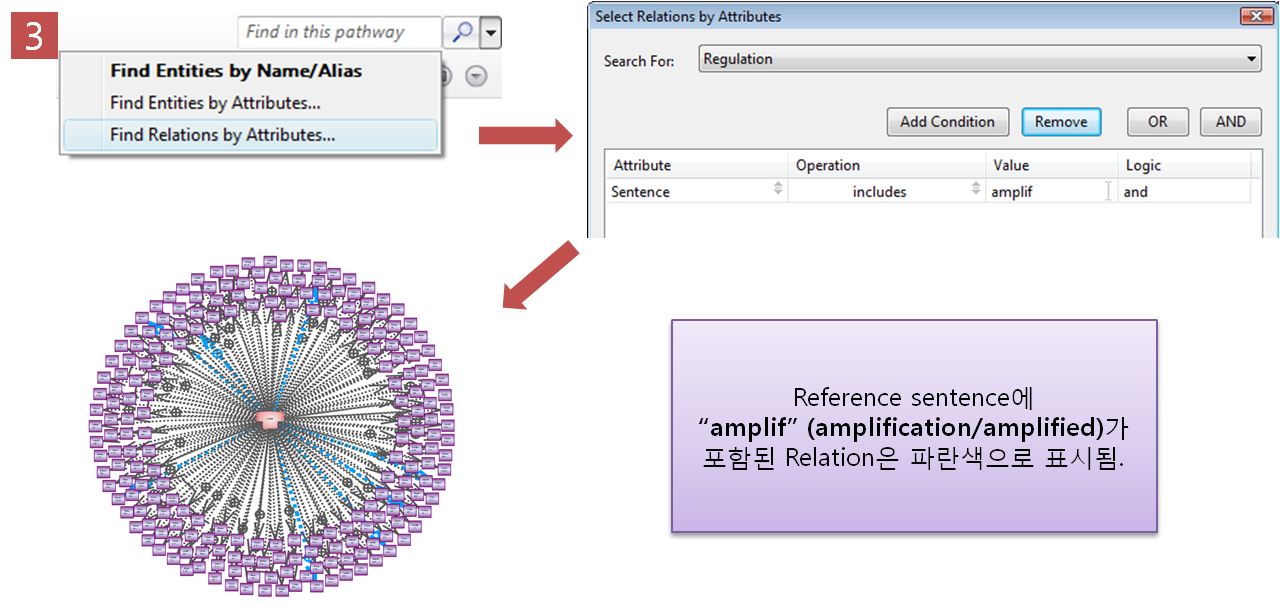
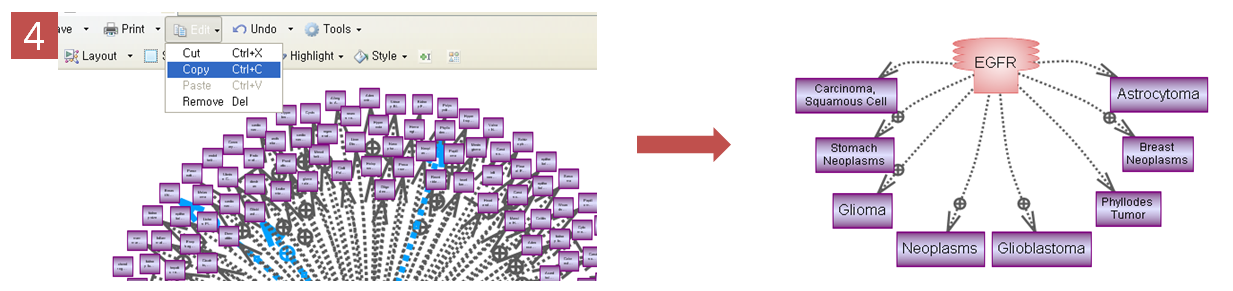
사람을 중요시 여기는 아름다운 기업 ㈜인실리코젠 Codes사업부 워크숍을 떠나다!
- Posted at 2012/08/08 15:18
- Filed under 회사소식

2012년 6월 1일 ㈜인실리코젠 Codes사업부는 신입 부서원들과의 단합과 더욱 효율적인 업무 수행을 위해 워크숍을 떠났습니다. 저 에겐 첫 출근과 동시에 떠나는 워크숍이라 기대에 많이 부풀어 있었습니다. 출근 첫날 강연경 선임님께서 인실리코젠의 식구들을 한 분 한 분 소개해 주셨습니다. 모든 人Co분들께서 웃으시면서 "안녕하세요?"라며 명함을 건내 주셨습니다. 아직까지 한분한분의 미소와 상냥함이 잊혀지지가 않습니다. 그리고 송하나 선배님의 도움으로 업무를 볼 수 있게 노트북 세팅 및 기초 위키 사용법에 대해서 알려 주셨습니다. 저희 Codes사업부는 오후 4시까지 업무를 보고 부랴부랴 짐 가방을 메고 충남 당진으로 출발하였습니다.
저와 강연경 선임님은 신윤희 선임님의 차를 타고 출발하였습니다. 출발한지 30분 즈음 웅장한 서해대교를 지나 간단히 허기를 채우기 위해 행담소 휴게소를 들렸습니다. 먼저 도착한 유원기 주임님과 정명희 선배님, 박혜선 선배님께서 저희를 기다리고 있었습니다. 간단한 먹거리를 사서 포토존에 앉아 아름다운 행담소 휴게소를 감상했습니다. 특히나 바다 옆에 위치해 시원한 바람과 유럽풍의 풍차, 새빨간 전화 부스, 천사의 날개 등 너무나 잘 꾸며져 있어서 지나가는 길목이면 꼭 다시 한번쯤 들리고 싶은 휴게소였습니다.
아쉬움을 뒤로한 채 목적지에 6시까지 도착해야 하기에 다시 저희는 목적지를 향해 출발하였습니다. 목적지에 도착하기 10분 즈음 남은 상황에서 이정표에 보이는 건 석문면!! 잘못 본 거라 생각하고 조금 지나가니 또다시 나타난 이정표에 "석문면 교로리 방향!!" 목적지가 당진군 석문면 교로리라는 것을 그제야 알았습니다. 우연한 일치인지 첫 출근에 첫 워크숍의 목적지가 저의 이름인 석문 면인 게 너무나 신기해 하는 찰라 목적지인 왜목마을에 도착하였습니다. 왜목마을을 간단히 설명하자면 서해에서 유일하게 일출, 일몰을 한 곳에서 감상할 수 있으며 한적하여 휴가지로도 인기 만점이랍니다.
그리고 도착한 곳! Codes사업부가 묵을 "꿈꾸는 펜션"을 소개합니다!!!


그리고 세미나를 위해 준비해 온 빔프로젝터를 심재영 주임님께서 세팅하시고 예정시간보다 약간 늦은 6시 30분경에 박준형 부장님 진행 아래 펜션 안 소박한 세미나가 시작되었습니다. 짝짝짝
Codes사업부는 Marketing팀, Research팀, SI 팀으로 구성되어 있습니다. 발표는 먼저 Marketing팀의 김경윤 주임님께서 Codes사업부의 상반기 매출 결과와 하반기 매출 계획에 대해 발표해 주셨습니다. 대부분 매출 즉 "금액"에 대한 내용이기 때문에 체감적으로 회사의 규모와 성장성에 대한 느낌을 잡을 수 있었습니다. 그리고 이번년도 매출계획을 달성하기 위해 저 또한 열심히 협업할 수 있게 최선을 다해야겠다라는 마음가짐을 가질 수 있었습니다. 그 다음으로 Research팀의 신윤희 선임님께서 현재 진행중인 사업과 진행될 사업에 대해 발표해 주셨습니다. 느낌점을 한마디로 표현하자면 역시 전문가가 많은 기업은 다르구나!라는 생각을 가장 먼저 하게 될 만큼 어마어마한 사업리스트들 보게 되었습니다. 마지막으로 제가 속한 SI 팀의 이규열 선임님께서 현재 이슈인 오믹스 사업, 바코드 사업, 농과원 사업에서 시스템 구축현황 및 진행예정에 대해 말씀해 주셨습니다. 아직은 신입사원이라 구체적인 것은 잘 모르지만 열심히 익혀서 SI팀을 이끌고 더 나아가 인실리코젠에서 핵심 개발자가 되리라 다짐했습니다. 마지막으로 박준형 사업부장님께서 각 팀의 내용에서 추가적으로 살을 덧붙여 주셨습니다. 그리고 저와 대전지사에서 7월부터 근무하게 될 양성진씨의 소개가 있었습니다. 양성진씨의 해맑게 웃으시는 모습이 너무나 인상깊어서 기억에 오래도록 남을 것 같습니다.

세미나를 모두 마치고 저녁을 먹으러 출발하기 전 펜션 앞 잔디에서 단체사진을 찍으려고 모두 포즈를 취하는데...
펜션 주인 아주머니께서 기르시는 집고양이가 "하나","두울","셋"하는 순간마다 매번 카메라를 가려서 겨우 단체사진을 찍을 수 있었습니다. 여러 번의 사진 촬영은 있었지만 처음보는 광경에 모두 웃음을 참지 못하고 여기저기서 웃음보가 터졌고 덕분에 모두 "스마일"하는 사진을 얻을 수 있었습니다.
일행 대부분 배에서는 밥 달라는 신호가 계속 울리고 저녁을 먹기 위해 바다 근처로 이동을 하였습니다. 주위에는 횟집들이 즐비하고 있었는데 배고픔을 참지 못하고 제일 처음으로 보이는 횟집으로 들어갔습니다. 자리배치를 하다 보니 조개구이 먹는 팀, 횟먹는 팀으로 나뉘게 되었고 제가 앉은 자리는 이규열 선임님과 박혜선 선배님, 양성진씨와 자리를 같이 했습니다. 주 요리가 나오기 전 무수히 많은 요리가 나왔고 서로의 술잔에 잔을 채우고 박준형 부장님의 건배 제의를 시작으로 화기애애한 분위기 속에 Codes사업부의 저녁 만찬은 계속되었습니다.

펜션으로 복귀 후 간단히 맥주를 마시며 이슈거리에 대해 이야기 하면서 즐거웠던 워크숍 첫날은 마무리되었습니다.
모두 허기진 배를 잡고 근처 해장국집을 들어갔습니다. 콩나물국밥과 갈비탕으로 맛있게 식사를 하면서 마친 후 여기까지 워크숍을 왔는데 바다를 안 보고 갈 수는 없었죠! 바로 옆 바다로 걸음을 향하였습니다. 눈부신 햇살과 여기저기에서 바람 쐬러 온 가족과 연인들! 정말 평화로움 그 자체였습니다. 저희 Codes사업부도 질 수 없죠! 따스한 햇빛을 먹은 모래사장을 한 발 한 발 걸으며 시원한 바닷바람을 온몸으로 맞으며 마지막 워크숍 순간을 만끽하였습니다.

해변에서 마지막으로 단체사진을 찍고 모두 모여 "수고하셨습니다"라는 함성과 함께 각자 목적지로
향하는 차를 타고 1박 2일의 아쉬운 워크숍은 마무리가 되었습니다. 저는 박 부장님의 차를 타고 회사 앞까지 오면서 부장님과의
오고 가는 대화 속에 인실리코젠에 대해 더욱더 잘 알 수 있었던 소중한 시간이었던것 같습니다.
저는 지금 입사한 지 6주차에 접어들었습니다. 처음 목표는 무엇보다 다른 직원분들과 친해지는 것이었습니다. 약간의 내성적인 성격으로
인해 완전히 친해지려면 조금 더 시간이 필요하겠지만 요즘은 웃으며 농담도 건내는 수준까지 왔습니다. 한분한분이 다들 적응을 빨리
할 수 있도록 세심한 관심을 기울여 주신 덕이라고 생각합니다. 또한 8월에 투입될 사업에 대비해서 서버세팅과 일주일 간의
웹개발에 필요한 교육도 강연경 선임님의 도움으로 무사히 마칠 수 있었습니다. 특히나 매일 오전 7시 강연경 선임님께서 스프링
프레임워크 교육을 해주셔서 기본적인 스프링의 동작방법 및 웹개발 시 프로그래밍하는 법을 많이 배울 수 있었습니다. 특히나
JSP에서는 깔끔하지 못했던 코드들이 스프링프레임 워크을 이용하면 깔끔하게 MVC (Model View Controller)로
분리가 되니 참 신기할 따름이었습니다. 지금은 생물자원관 웹 개발하시는 석호동 대리님을 도와 다국어 메시지 처리부분을 담당하고
있습니다.
아직까지 회사에 대해 완벽히 파악하진 못했지만 어느 정도의 일을 하고 있고, 어느 분야에 포커스가 맞추어져 있는지는 알 수 있었습니다. 그리고 6주간 많이 사고도 쳤지만 배우면서 성장하는거야! 다음부턴 사고치면 안돼!라
는 선임님께서 따뜻한 말을 많이 해주셨습니다. 실수를 할 때마다 가슴도 조이지만 다시금 같은 실수를 하지 않겠노라 다짐하며
하루하루의 일정을 확인하고 놓치지 않지 위해서 메모하는 습관을 키우고 있습니다. 6주간의 시간동안 느낀 인실리코젠은 탄탄한
기업임은 부정할 수 없는 사실이고 그 외에 인간을 중시하는 따뜻하고 포근한 회사였습니다. 또한 여러 분야의 많은 전문가들이
소속되어 있으며 모두들 본인의 일을 즐겁게 즐기면서 꿈을 키워 나가는 모습은 어느 회사를 가도 보지 못하는 광경일 것 같습니다.
아직 인턴 기간이지만 1년 3년 5년 10년을 내다보며 인실리코젠에서 좋아하는 일을 하며 소중한 사람들과 함께하고 싶습니다.
이 글을 읽어주신 모든 분께 감사드립니다. 앞으로 열심히 잘하는 사원이 되겠습니다.Posted by 人Co
- Tag
- insilicogen, 인실리코젠
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/117