
교배 육종에서 디지털 육종으로
- Posted at 2021/01/31 00:37
- Filed under 지식관리

인류에게 종자는 가장 기본이 되는 일차적 요소로서 오늘날 세계 종자시장 규모는 유례없이 빠른 성장세를 보이고 있습니다.
현재 국내 관계부처에서는 농, 수, 축산 분야에서 아날로그식 교배 육종에서 디지털 육종으로 종자 산업의 패러다임 전환을 예상하고 관련 사업을 적극적으로 지원하고 있는데요, 오늘 블로그는 이러한 디지털 육종에 대해 알아보도록 하겠습니다.

오늘 점심으로는 무엇을 드셨나요? 전주 한정식에 올라온 한끼 메뉴에 영양 많은 강낭콩이 들어간 돌솥밥에 불고기, 조기구이, 호박나물, 잡채, 신선한 굴까지 26개의 반찬이 올라왔습니다. 식자재로 따져 보면 마늘, 파, 고추, 계란 등 아마도 족히 50가지는 넘을 것 같습니다. 우리는 이런 식자재를 마트나 새벽 배송을 통해서 언제나 쉽게 구할 수 있죠. 어떻게 가능했을까요? 너무 쉬운 일이라 고민해볼 여지도 없는 것이겠지만, 이것은 모두 육종 덕분입니다. 곡류를 비롯한 채소류, 육류(소, 돼지, 닭 등), 수산물(넙치, 전복, 고등어)까지 모두 육종을 통해 농장과 양식장에서 생산성 높게 길러지고 있음을 우리는 잘 알고 있습니다.
 [Fig. 1] 전주한정식
[Fig. 1] 전주한정식단적인 예로 쌀의 경우 여리고 키가 크며 붉은색 쌀알이던 야생벼에서 현재의 튼실하고 흰 쌀알로 육종되었으며, 콩도 땅에 기어 자라던 야생종에서 현재의 위로 자라는 종으로 육종되어 생산성이 매우 높아지게 되었습니다. 이렇듯 오랜 세월 우리 주변의 동·식물을 우리가 선호하는 형태로 변화시킨 육종은 오늘날 점점 더 가속화, 세분화되고 있습니다. 닭의 경우만 보더라도 계란을 얻으려는 목적의 알을 잘 낳는 닭과 닭고기를 얻으려는 목적의 빠른 성장과 근육이 많은 닭으로 각각 세분화하여 목적에 부합하는 형태로 육종되었습니다.

[Fig. 2] 재배벼의 조상인 여러 가지 야생벼와 재배벼

[Fig. 3] 야생콩과 재배콩 (출처 Jeong-et-al., 2013)

그럼 육종 방법에 대해 좀 더 자세히 알아보겠습니다.
- 도입 육종 : 기후나 풍토가 유사한 다른 나라에서 개발된 품종을 국내로 도입하여 검역과 검정평가를 통해 증식시키는 육종으로, 1959년 미국에서 도입한 옥수수가 대표적입니다.
- 교배 육종 : 서로 다른 우수한 형질을 갖는 개체들을 교배하여 한 개체에서 우수한 형질 모두를 가질 수 있도록 하는 것으로, 대부분의 전통 육종방식이 이에 해당합니다. 육종가들에 의해 수년 동안 반복적인 교배와 표현형에 의한 개체 선발 과정이 수반되는 터라 시간적, 공간적, 비용면에서 효율성이 낮다는 단점이 있습니다.
- 형질 전환 육종 : 유전자 재조합 방식을 이용해 관심 형질 유전자를 유전체에 도입하는 방식으로 기존의 생명체에서 없던 형질을 갖도록 종을 개량합니다. 흔히 GMO(Genetically Modified Organism)와 LMO(Living Modified Organism)를 들 수 있는데(유전자 재조합을 통해 변형된 생물체를 LMO로 한정하고 이들 생명체를 제조, 가공한 것까지 포함한 것을 GMO로 함), 제초제 내성을 갖는 콩이나 냉해에 강한 딸기, 옥수수 등이 이에 해당합니다. 인류가 섭취해온 이력이 없는 단백질을 포함하고 있어 알레르기 반응을 포함한 알려지지 않은 문제의 가능성 때문에 심리적으로 불편함을 느끼는 이슈가 있습니다.
- 디지털 육종 : 유전형-표현형에 기반을 둔 선발 육종 방식으로 다양한 표현형을 갖는 집단에서 특정 형질(표현형)을 갖는 개체들만을 유전형을 이용하여 선발하는 방식입니다. 최근 6~8년 걸리던 호박의 새 품종 개발을 3년 이하로 줄일 수 있었던 첨단 육종 기술입니다.
이렇게 간단히 살펴본 육종 기술 가운데, 현재 가장 발전된 기술은 디지털 육종이라 불리는 유전형 기반의 육종입니다.
NGS (Next generation sequencing)라는 대용량 시퀀싱 기술로 유전체 서열을 밝히고, 표현형이 다양한 개체들의 변이 정보를 생산함으로써 표현형과 연관된 유전형을 찾아 마커로 개발하는 방식은 기존의 다른 육종 기술의 단점들을 대부분 보완하고 있습니다.
가장 전통적으로 진행해 오던 교배 육종은 교배된 F1 세대부터 다수의 개체를 키워가며 목표 표현형에 부합되지 않는 개체들을 솎아내며 몇 세대가 될지 모를 목표 형질에 다다를 때까지 교배와 솎아냄을 반복합니다. 그러다 보니 시간적으로나 물리적으로 필요한 재배 환경까지 비용면에서 효율성이 낮았습니다. 게다가 전복과 같이 3년은 키워야 비로소 교배가 가능한 종일 경우, 소처럼 다음 세대의 개체수가 극히 적은 경우 (1마리의 새끼만을 낳는 경우), 과실수와 같이 한세대가 너무 길어 표현형을 확인하는 데 몇 년씩 걸리는 경우들은 교배 육종으로는 한계가 있습니다. 그에 반해 디지털 육종은 현재 관찰 가능한 개체들을 대상으로 선발하기 때문에 공간적, 시간적 제약에서 비교적 자유롭습니다.
형질 전환 육종에서의 이슈는 생명 현상의 대부분이 여러 유전자의 복합적인 상호작용으로 이뤄지기 때문에 유전자 하나를 도입한다고 해서 해당 형질이 바로 얻어지지 않는 단점이 있습니다. 도입된 유전자가 발현되어 단백질이 되었을 때 세포 내의 다른 단백질과 혹은 다른 유전자들과 어떤 상호 작용을 하느냐에 따라 표현형은 다르게 나타날 수 있기 때문입니다. 따라서 목표 유전자를 선택하고 제어하는데 생물학적 메커니즘의 이해가 수반되어야 하는 어려움이 있습니다. 그러나 디지털 육종은 자연적으로 생겨난 개체들 가운데 목표 형질을 갖는 개체를 선발하는 방식이라 유전자 재조합에 대한 불편함 및 생물학적 메커니즘 이해가 필요하지 않습니다.

그럼 디지털 육종에 대한 보다 정확한 이론을 살펴보겠습니다.
디지털 육종에는 필수 요소 3가지가 있습니다. 개체 (샘플), 표현형, 유전형이 그것인데, 모두 앞선 기술들에 비해 수집하는 데 유리합니다.
먼저 개체 확보 면에서 디지털 육종은 현재 관찰이 가능한 모든 개체를 대상으로 합니다. 야생종부터 돌연변이 종까지 제한이 없으며, 동일한 생장 조건이 필요하지도 않습니다. 예를 들어 밤나무의 경우 전국의 수집 가능한 모든 밤나무가 대상이 될 수 있습니다. 나무의 연령이 모두 달라도 괜찮습니다. 호박과 같은 채소류의 경우 일부러 교배를 통해 다양한 개체를 얻었다면 그 또한 모두 가능합니다.
두 번째, 표현형 정보는 현재 확보된 개체들에서 관찰되는 모든 것을 대상으로 할 수 있습니다. 밤나무의 경우 알곡의 크기, 밤나무가 위치한 지역, 수확 시기, 나무의 크기, 한 가지에 달리는 밤송이의 수, 나무의 연령 (가능하다면) 등 현재 시점에서 관찰할 수 있는 모든 것이 표현형으로 정리될 수 있습니다. 이를 좀 더 효율적으로 수집하고자 하는 기술이 Edging computing을 이용한 디지털화된 장비를 이용한 표현형 수집입니다. 온실에 카메라를 설치하고 주기적으로 사진을 촬영하여 호박의 성장 정보를 영상 분석을 통해 처리하는 AI 기술이 접목된 스마트 팜이 이에 해당합니다.
마지막인 세 번째 유전형 생산은, NGS 기술과 생물정보의 발달로 누구나 쉽게 얻을 수 있게 되었습니다. 심지어 오늘 드신 모든 식재료의 유전체가 밝혀져 있다는 사실만 보아도 얼마나 보편화된 기술인지 알 수 있습니다. 이들 3요소가 모두 데이터로 갖춰졌다면 총 4단계의 생물정보 분석을 통해 육종이 이뤄집니다.
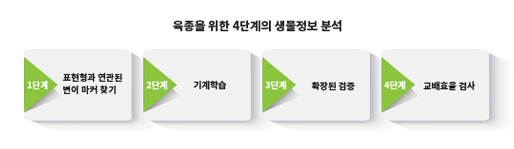
[Fig. 4] 육종을 위한 4단계의 생물정보 분석

- [1단계] 표현형과 연관된 변이 마커 찾기 : GWAS(Genome Wide Association Study)라 불리는 일종의 통계 분석으로 특정 표현형으로 집단을 구분한 후에 구분된 집단과 연관성이 높은 변이를 찾아내는 방법입니다. 이때, 표현형은 꼭 두 개의 집단으로 양분되는 구조가 아니어도 됩니다. 밤 알곡의 크기는 정량적인 수치로 크기에 따라 동일한 패턴으로 유전형이 나타난다면, 해당 변이는 알곡 크기에 연관된 마커로 선택될 수 있습니다. 병 저항성의 경우에도 잎의 60%가 마르는 데 걸리는 시간으로 표현형을 정량화할 수 있습니다.
- [2단계] 기계학습 : 표현형에 따른 집단의 구분력을 보이는 변이만을 유전형 데이터로 활용하여 표현형-유전형 기계학습을 수행합니다. 이때, 수집된 개체의 75% 정도를 학습 데이터로 활용하고, 나머지 25%는 학습된 기계학습의 정확도 평가를 위해 사용합니다. 밤 알곡의 크기를 예측하기 위한 기계학습을 예로 들면, 1단계에서 선별된 변이 마커가 30개라면, 개체별 30개의 유전형 정보에 따라 측정된 알곡의 크기를 표현형 정보로 학습되도록 합니다. 이후 구축된 예측모델을 이용해 남겨 두었던 25% 개체의 유전형 정보를 넣고 해당 표현형이 예측될 가능성이 얼마나 될지 확률치를 얻게 됩니다. 기계 학습의 평가는 True Positive (정답을 정답으로 예측), False Negative (오답을 오답으로 예측)로 계산되는 Specificity와 Sensitivity로 정리됩니다. 만약 결과가 만족스럽지 못하다면, 기계학습 알고리즘을 변경해 보거나 학습 데이터를 변경해야 합니다. 학습에 이용되는 30개 마커의 유전형 정보는 개체별로 모두 다를 수 있습니다. 이는 마커 개개의 정보력이 약하기 때문인데, 다수의 개체에서 기계학습을 통한 반복적인 학습을 통해 조금씩 다른 유전형임에도 동일한 표현형으로 학습시켜 정확도를 높일 수 있습니다. 또한, 마커 개별의 정보력이 약한 것은 오히려 한두 개의 변이 정보가 소실된다 할지라도 기계학습의 표현형 예측에는 큰 변수가 되지 않아, 기존의 SSR과 같은 분자 마커를 활용한 육종보다 한 단계 진보한 기술이라 할 수 있습니다.
- [3단계] 확장된 검증 : 구축된 기계학습모델로 더 많은 개체에 적용해 봅니다. 해당 표현형을 예측하는 데 사용되는 마커는 1단계에서 30개로 선별되었고, 이후 미지의 시료에 대해 30개 마커 유전형만을 타입핑하여 표현형을 예측합니다. 이는 여러 출처의 개체로 검증해보는 것이 좋습니다.
- [4단계] 교배효율 검사 : 기계학습모델 검증이 완료되었다면 최적의 교배 지침을 위한 F1 세대의 표현형 예측 시뮬레이션을 진행합니다. 부·모가 될 개체의 유전형을 기반으로 F1 세대에서 나타날 수 있는 유전형을 무작위 방식 구성합니다. 이때 F1 세대의 개체수는 2,000개체 이상, 유전형은 해당 표현형을 예측하는 마커 수, 앞선 예로 들자면 30개 유전형을 인실리코상에서 데이터로 생산합니다. 이후 2,000 개체의 유전형을 이용해 구축된 기계학습으로 표현형을 예측하여 F1 세대에서 해당 표현형을 가질수 있는 평균 개체수가 어느 정도 되는지 수치화합니다. 이러한 방식으로 F1 세대에서 해당 표현형을 가질 수 있는 개체수가 많은 순서로 교배 조합을 시뮬레이션합니다. 어패류의 경우 교배를 위해 다수의 친어를 수조에 넣어 진행하고, 체외 수정을 하는 종이기 때문에 이러한 교배효율 시뮬레이션은 다음 세대의 육종 효율을 높이는 데 매우 중요합니다.
최근 종자의 중요성이 대두되면서, 육종에 대한 한 차원 발전된 기술의 적용이 범국가적으로 진행되고 있습니다. 디지털 육종이라 불리는 신기술은 이제 표현형-유전형으로 대두되는 데이터 육종으로 진화해 가고 있습니다. 따라서 비록 지금은 정보력이 낮은 표현형 하나하나도 모두 데이터화 하려는 노력이 필요합니다. 육종은 살아있는 생명체에 행해지는 것입니다. 우리가 먹지 않는 사료로 이용되는 옥수수라 할지라도 유전적 변형이 행해지게 되면, 생태에 변화를 초래할 수 있어 매우 조심스럽게 접근해야 하는 분야입니다. 그런 면에서 데이터 육종은 자연스레 발생된 개체들 가운데 유전형을 이용한 선발 방식이라 안정적입니다. 안전하게 자연의 일부로 존재하는 육종을 위해 데이터 육종은 앞으로 더욱 데이터를 쌓아 가야할 것입니다.
작성 : RDC 신윤희 책임 연구원
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/370
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

