
탐색적 데이터 분석 (Exploratory Data Analysis)
- Posted at 2020/11/08 16:34
- Filed under 지식관리

4차 산업의 핵심 기술인 빅데이터(Big Data)는 인공지능(AI), 사물인터넷(IoT), 증강현실(AR), 가상현실(VR) 등과 함께 필수적인 요소로 평가받고 있습니다. 이러한 빅데이터를 이용하여 크고 복잡한 현상에서 의미 있는 패턴을 찾고, 의사 결정에 필요한 통찰을 얻는 데이터 분석이 중요해지고 있습니다. 데이터 분석에는 크게 두 가지의 접근방법이 있습니다.
먼저 확증적 데이터 분석(CDA: Confirmatory Data Analysis)은 가설을 설정한 후, 수집한 데이터로 가설을 평가하고 추정하는 전통적인 분석입니다. 관측된 형태나 효과의 재현성 평가, 유의성 검정, 신뢰구간 추정 등의 통계적 추론을 하는 분석 방법으로 설문조사나 논문에 관한 내용을 입증하는 데 사용됩니다.
두 번쨰로 탐색적 데이터 분석(EDA: Exploratory Data Analysis)은 원 데이터(Raw data)를 가지고 유연하게 데이터를 탐색하고, 데이터의 특징과 구조로부터 얻은 정보를 바탕으로 통계모형을 만드는 분석방법입니다. 주로 빅데이터 분석에 사용됩니다. 확증적 데이터 분석은 *추론통계로, 탐색적 데이터 분석은 *기술통계로 나누어 볼 수 있습니다.
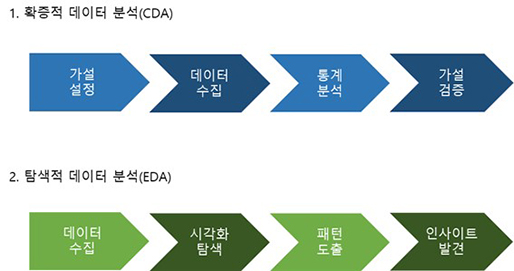
[Fig.1] 확증적 데이터 분석(CDA)과 탐색적 데이터 분석(EDA)
오늘은 이 중에서 탐색적 데이터 분석에 관하여 이야기해 보고자 합니다.
- 추론통계 – 수집한 데이터를 이용하여 추론 예측하는 통계 기법으로 신뢰구간 추정, 유의성 검정 기법 등을 이용함
- 기술통계 – 수집한 데이터를 요약 묘사 설명하는 통계 기법으로 데이터의 대푯값, 분포 등을 이용함

“ '탐색적 데이터 분석(EDA)’은 우리가 존재한다고 믿는 것들은 물론이고 존재하지 않는다고 믿는 것들을 발견하려는 태도, 유연성, 그리고 자발성이다. “ - 존 튜키 (도서 Doing Data Science 중)
탐색적 데이터 분석이란 벨 연구소의 수학자 존 튜키가 제안한 데이터 분석 방법으로 통계적 가설 검정 등에 의존한 기존 통계학으로는 새롭게 나오는 많은 양의 데이터의 핵심 의미를 파악하는 데 어려움이 있다고 생각하여 이를 보완한 탐색적 데이터 분석을 도입했다고 합니다. 데이터를 분석하고 결과를 내는 과정에서 원 데이터에 대한 탐색과 이해를 기본으로 가지는 것이 가장 중요합니다. 이에 따라 탐색적 데이터 분석은 데이터의 분포와 값을 다양한 각도에서 관찰하며 데이터가 표현하는 현상을 더 잘 이해할 수 있도록 도와주고 데이터를 다양한 기준에서 살펴보는 과정을 통해 문제 정의 단계에서 미처 발견하지 못한 다양한 패턴을 발견하고 이를 바탕으로 기존의 가설을 수정하거나 새로운 가설을 추가할 수 있도록 합니다. 데이터에 대한 관찰과 지식이 이후에 통계적 추론이나 예측 모델 구축 시에도 사용되므로 데이터 분석 단계 중 중요한 단계라고 할 수 있습니다. EDA의 목표는 관측된 현상의 원인에 대한 가설을 제시하고, 적절한 통계 도구 및 기법의 선택을 위한 가이드가 되며, 통계 분석의 기초가 될 가정을 평가하고 추가 자료수집을 위한 기반을 제공합니다.

탐색적 데이터 분석은 한 번에 완벽한 결론에 도달하는 것이 아니라 아래와 같은 방법을 반복하여 데이터를 이해하고 탐구하는 과정입니다.
-
(1) 데이터에 대한 질문 & 문제 만들기
(2) 데이터를 시각화하고, 변환하고, 모델링하여 그 질문 & 문제에 대한 답을 찾아보기
(3) 찾는 과정에서 배운 것들을 토대로 다시 질문을 다듬고 또 다른 질문 & 문제 만들기
이러한 과정을 기반으로 데이터에서 흥미 있는 패턴이 발견될 때까지, 더 찾는 것이 불가능하다고 판단될 때까지 도표, 그래프 등의 시각화, 요약 통계를 이용하여 전체적인 데이터를 살펴보고 개별 속성의 값을 관찰합니다. 데이터에서 발견되는 이상치를 찾아내 전체 데이터 패턴에 끼치는 영향을 관찰하고, 속성 간의 관계에서 패턴을 발견합니다.
1. 전체적인 데이터 살펴보기
데이터 항목의 개수, 속성 목록, NAN 값, 각 속성이 가지는 데이터형 등을 확인하고, 데이터 가공 과정에서 데이터의 오류나 누락이 없는지 데이터의 head와 tail을 확인합니다. 또한, 데이터를 구성하는 각 속성값이 예측한 범위와 분포를 갖는지 확인합니다.
2. 이상치(Outlier) 분석
먼저 앞서 실습했던 방법으로 개별 데이터를 관찰하여 전체적인 추세와 특이사항을 관찰합니다. 데이터가 많다고 특정 부분만 보게 되면 이상치가 다른 부분에서 나타날 수도 있으므로 앞, 뒤, 무작위로 표본을 추출해서 관찰해야 합니다. 이상치들은 작은 크기의 표본에서는 나타나지 않을 수도 있습니다. 두 번째로는 적절한 요약 통계 지표를 사용합니다. 데이터의 중심을 알기 위해서는 평균, 중앙값, 최빈값을 사용하고, 데이터의 분산도를 알기 위해서는 범위, 분산 등을 이용합니다. 통계 지표를 이용할 때에는 평균과 중앙값의 차이처럼 데이터의 특성에 주의해서 이용해야 합니다. 세 번째로는 시각화를 활용합니다. 시각화를 통해 데이터의 개별 속성에 어떤 통계 지표가 적절한지를 결정합니다. 시각화 방법에는 Histogram, Scatterplot, Boxplot, 시계열 차트 등이 있습니다. 이외에도 기계학습의 K-means 기법, Static based detection, Deviation based method, Distance based Detection 기법을 이용하여 이상치를 발견할 수 있습니다.
3. 속성 간의 관계 분석
속성 간의 관계 분석을 통해 서로 의미 있는 상관관계를 갖는 속성의 조합을 찾아냅니다. 분석에 대상이 되는 속성의 종류에 따라서 분석 방법도 달라져야 합니다. 변수 속성의 종류는 다음과 같습니다.

[Fig.2] 데이터의 종류
먼저 이산형 변수- 이산형 변수의 경우 상관계수를 통해 두 속성 간의 연관성을 나타냅니다. Heatmap이나 Scatterplot을 이용하여 시각화할 수 있습니다. 다음으로 이산형 변수 - 범주형 변수는 카테고리별 통계치를 범주형으로 나누어서 관찰할 수 있고, Box plot, PCA plot 등으로 시각화할 수 있습니다. 마지막으로 범주형 변수- 범주형 변수의 경우에는 각 속성값의 쌍에 해당하는 값의 개수, 분포를 관찰할 수 있고 Piechart, Mosaicplot 등을 이용하여 시각화할 수 있습니다.

사례를 통해 살펴보겠습니다. jupyter notebook 환경 안에서 pandas를 이용하여 진행하였습니다. 분석에 사용한 데이터는 iris data입니다
iris (붓꽃) data는 통계학자인 Fisher가 공개한 데이터로 iris의 3가지 종(setosa, versicolor, virginica)에 대해 꽃받침과 꽃잎의 넓이와 길이를 정리한 데이터입니다. 종별로 50개씩 150개체의 데이터가 있으며 기계학습 중 분류(Classification)에 적합한 데이터입니다. 데이터의 크기가 작고 이해가 쉬운 데이터이고 R이나 Python 머신러닝 패키지인 Scikit-learn 에서 쉽게 접근할 수 있는 데이터이기에 해당 데이터로 분석을 진행해 보았습니다.
-
데이터 첨부 iris_dataset.csv
-
jupyter스크립트 InsilcoLog_EDA_jupyter.ipynb
1. 데이터 읽어오기
df.to_csv('iris_dataset.csv', index=False)
2. 전체적인 데이터 살펴보기
shape, dtype 함수를 통해 데이터 항목의 개수와 type을 알아보겠습니다.
print(df.shape) # 데이터의 행, 열 개수 출력 print(df.dtypes) # 데이터의 타입 출력

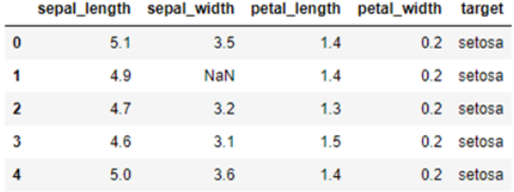
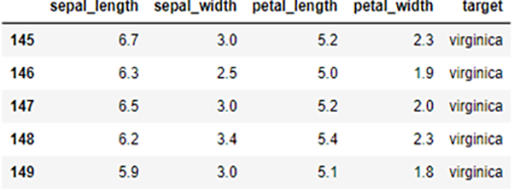
head, tail 함수를 이용해서 앞 5행, 뒤 5행의 데이터를 살펴보도록 하겠습니다.
df.head() # 앞 5행 출력 df.tail() # 뒤 5행 출력
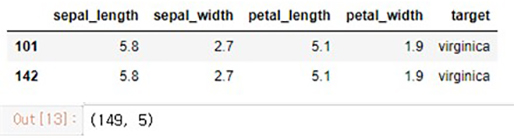
df[df.duplicated(keep=False)] # 중복된 열 출력 df = df.drop_duplicates() # 중복된 열 제거 df.shape() #제거된 열 확인
isna 함수로 Nan 값을 값별로 True, False 형태로 확인하고 열별로 Nan값을 sum 함수로 더해 한 눈에 확인 해 보겠슶니다. dropna 함수로 Nan값을 제거하거나, fillna로 Nan값을 다른 값으로 치환할 수 있습니다.
df.isna() #Nan값이 있는지 출력 True, False 형태로 출력됨 df.isna().sum() # 열별 Nan값을 출력함 df = df.dropna() #Nan값을 제거 fillna()함수로 Nan값을 치환할 수도 있음 df.shape() #제거된 열 확인

3. 이상치(Outlier) 분석
describe 함수를 통해 각 컬럼별로 요약 통계 (갯수, 평균, 표준편차, 최솟값, 최댓값과 4분위수)를 수치값으로 확인할 수 있습니다.
df.describe() # 각 컬럼별 요약 통계 지표 출력
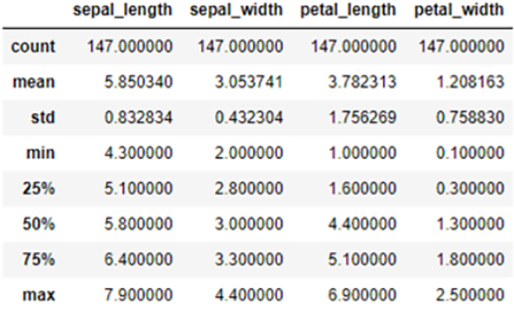 [Fig.8] iris 데이터 셋의 요약 통계 지표
[Fig.8] iris 데이터 셋의 요약 통계 지표

4. 속성 간의 관계 분석
상관계수를 통하여 두 속성 간의 연관성을 나타낼 수 있습니다. -1 에 가까우면 음의 상관관계, 0 이면 상관관계가 없고 1은 양의 상관관계를 나타냅니다. 이를 Heatmap으로 시각화하여 확인할 수 있습니다.
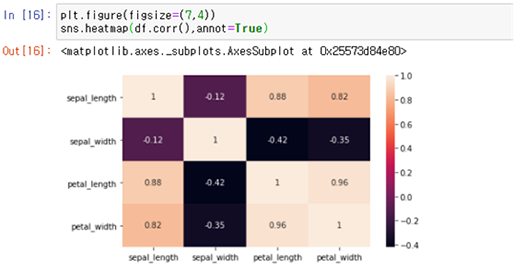
[Fig.12] 상관계수 및 Heatmap
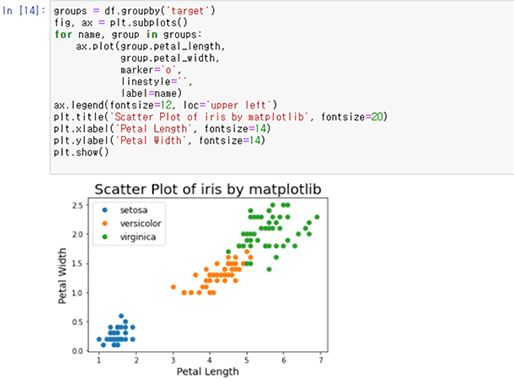
Pairplot은 데이터의 모든 컬럼들의 변수의 상관관계를 histogram과 Scatterplot으로 출력합니다. 전체 데이터의 상관관계를 한눈에 볼 수 있습니다.
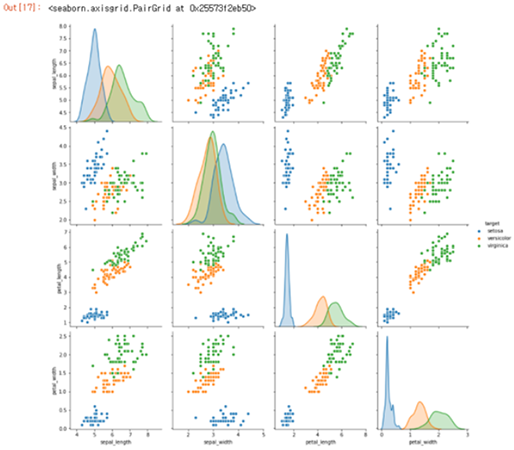
[Fig.13] Pairplot
위의 boxplot으로는 단변량 변수의 수치를 시각화하여 확인하였다면, 이 변량 변수를 사용하여 상관성을 볼 수도 있습니다.

[Fig.14] Boxplot
PCAplot은 여러 변수의 변량을 주성분(Principal Component, 서로 상관성이 높은 여러 변수의 선형 조합으로 만든 새로운 변수)으로 요약, 축소하는 방법으로 먼저 Screeplot을 이용하여 주성분의 수를 정하고 이를 바탕으로 아래와 같은 PCAplot, Biplot을 그려 분포와 주성분 간의 관계를 확인합니다. 각 주성분이 차지하는 분산의 누적비율을 계산해서 각 주성분이 전체 분산 중 얼마만큼 설명해 주는지를 알 수 있습니다.
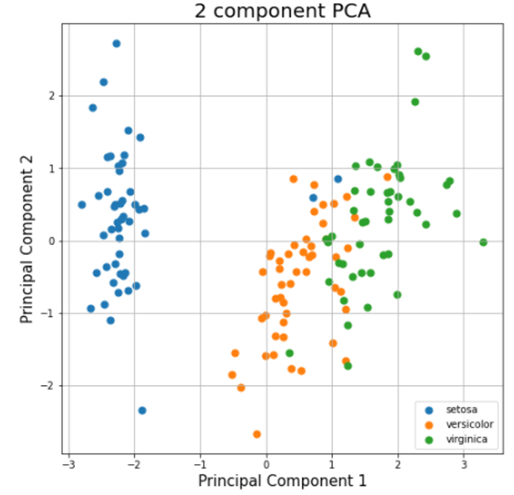
[Fig.15] PCAplot

탐색적 데이터를 공부하면서 ‘맛있는 요리’를 만들기 위해서는 가장 먼저 ‘맛있는 음식재료’를 준비해야 하듯이 데이터 분석에서 맛있는 음식재료라고 할 수 있는 EDA가 중요하다는 말이 인상 깊었습니다. 가장 기본적인 원 데이터를 다양한 방면에서 데이터를 관찰하면서 인사이트를 이끌어 낼 수 있다는 것이 EDA의 큰 장점인 것 같습니다. 위의 실습 스크립트도 함께 첨부하니 함께 공부할 수 있으면 좋겠습니다! 이번 블로그를 통해서 탐색적 데이터 분석의 전반적 흐름과 중요성을 알 수 있는 시간이 되었으면 좋겠습니다. 감사합니다.

-
https://en.wikipedia.org/wiki/Exploratory_data_analysis#cite_note-5
-
https://towardsdatascience.com/pca-using-python-scikit-learn-e653f8989e60
-
https://www.kaggle.com/rakesh6184/seaborn-plot-to-visualize-iris-data
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/361
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

