검색엔진최적화(Search Engine Optimization, SEO)
- Posted at 2018/12/31 09:08
- Filed under 정보공유

검색엔진 최적화(Search Engine Optimization, SEO) 란?
SEO (Search Engine Optimization 검색엔진 최적화)는 웹 페이지 검색엔진이 자료를 수집하고 순위를 매기는 방식에 맞게 웹 페이지를 구성하여 잠재 고객(사용자)을 더 많이 사이트로 유입하기 위한 작업이며 특정 키워드로 검색엔진에 상위 노출을 진행하는 관점에서, 웹사이트를 검색엔진 알고리즘에 최적화하여 검색결과 상위에 표시하기 위한 일종의 사이트를 최적화하는 마케팅 방법입니다.

위의 [그림2]에서 SEO를 적용하게 되면 초기 개발비는 일반 개발비보다 높을 수 있습니다. 하지만 일반 홈페이지가 개발 완료 후 홍보목적으로 광고비를 들여서 네이버 또는 구글에 상위페이지에 올리는 것에 비하여 SEO가 적용된 홈페이지는 별도의 광고비 없이 키워드 검색만으로도 상위에 홈페이지를 올려 방문자 수도 올리고 자연스럽게 회사홍보 및 매출에도 영향을 끼칠 수 있을 것입니다.

적용방법
국내외 주요 검색엔진인 구글(Google)과 네이버(Naver)가 각각 공개하는 검색엔진 최적화 가이드를 중심으로 한 적용법을 살펴보겠습니다.
1. 콘텐츠의 질과 양이 최우선
첫 번째로 키워드 최적화로 홈페이지에 잠재 고객의 유입을 늘린다고 하더라도 콘텐츠의 내용이 적고 관련 없는 내용을 올린다면 오히려 역효과가 나서 고객을 잃을 수 있으니 방문자가 다시 방문할 수 있는 양질의 콘텐츠가 필요합니다.2. 적절한 연관 키워드 활용 및 배치
콘텐츠의 관련 키워드 최적화 작업에서 내용과 관련 없는 마구잡이 식의 키워드 선정은 좋지 않습니다. 내용과 맞는 적절한 키워드 선정은 무엇보다도 중요한 작업입니다.3. 제목(title) 태그의 사용
내용의 title 태그나 강조의 strong 태그를 20자 이내로 작성하는 것이 좋습니다. 한번 사용한 키워드의 제목을 반복하지 않으며 다른 페이지의 같은 제목을 사용하지 않아야 합니다. 또한, 특수문자를 자제하는 최적화 작업이 진행돼야 합니다.4. 이미지 태그에는 이미지에 맞는 키워드를 ALT 속성으로 기재
상품이나 기업 이름 등을 이미지 태그로 표현하게 되면 검색엔진이 이미지를 인식하지 못함으로 alt 속성을 넣어 적절한 대체 텍스트를 기재하여야 합니다.5. META 태그 기재
META 태그의 정보는 검색결과 우선순위에 중요한 요소입니다. 그러므로 해당 페이지의 내용을 정확히 파악하면서 내용에 맞는 키워드를 기재해 두는 것이 좋습니다. 또한, 키워드의 구분은 콤마를 사용해야 합니다.6. 플래시 전용 페이지 자제
검색 엔진은 Flash 애니메이션 속의 텍스트를 수집할 수 없으며, 그 링크 또한 사용할 수 없으므로 사용을 지양하는 게 좋습니다.7. 검색하는 사용자의 입장이 되어 생각
대기업이 아닌 일반 인지도가 없는 기업이나 상품의 경우 웹사이트에서 상품명 등의 고유 명사로 하는 것보다 키워드 설정 시 일반적인 단어로 기재하여야 잠재고객의 접근을 최대로 이끌 수 있습니다.8. 쉽게 이해할 수 있는 URL 사용
페이지의 URL 설정 시 페이지와 연관되는 단어를 사용하여 URL을 구성하는 것이 좋습니다. 이는 검색엔진의 최적화뿐 아니라 사용자에게도 페이지의 의미를 조금 더 쉽게 이해할 수 있도록 합니다. 예로, 스포츠 뉴스에 대한 정보를 검색하는 경우 https://sports.news.naver.com와 같은 URL은 이해하기 쉽고 접속을 유도 할 수 있습니다. 그에 비해 http://www.navaer.com/sportsNw와 같은 약어 URL은 사용자가 인식하기 쉽지 않으며 혼란스럽게 할 수 있습니다.9. 검색로봇에 대한 대응
robots.txt라는 파일을 이용하여 검색엔진이 사이트에서 접근할 수 있는 페이지와 접근할 수 없는 페이지를 정해놓은 검색엔진과의 규약을 만듭니다. 기본적으로 검색로봇이 접근할 수 없게 하는 페이지를 이 파일 양식 속의 넣고 기록하며 반드시 폴더 root에 위치해야 파일설정이 적용될 수 있습니다. robots.txt에 대한 상세한 내용은 http://www.robotstxt.org/ 에서 확인할 수 있습니다.10. 반응형 웹 디자인 적용
웹 브라우저가 웹 문서의 가로 폭을 기기의 스크린 크기에 맞게 자동으로 조절하는 기법으로, 사용자 기기 (데스크톱, 태블릿, 모바일, 비시각적 브라우저)와 상관없이 같은 URL에 같은 HTML 코드를 게재하지만 화면 크기에 따라 다르게 렌더링(응답)할 수 있습니다. 반응형 웹 디자인은 Google에서 권장하는 디자인 패턴입니다.
성공 사례
나이키 골프

나이키 골프는 나이키의 부진으로 인해 새로운 라인의 추가로 나이키 골프를 론칭하였고 골프공, 클럽, 셔츠, 신발 등을 판매하였습니다. 초기에 나이키는 나이키 골프의 노출과 가시성을 높여 매출을 높이기 위해 검색엔진 최적화를 적용하여 마케팅 하였습니다. 골프를 중심으로 한 키워드 사용을 개선하였으며 양질의 내용에 콘텐츠들을 제공하여 웹사이트를 제작하였으며 결과적으로 최적화 후 전년 대비 웹트래픽이 169%나 증가하였고 사이트 트래픽이 250% 증가하며 브랜드 마케팅에 성공하였습니다.
폭스바겐

폭스바겐은 검색엔진 최적화(SEO)를 통한 기발한 마케팅을 시도했습니다. 구글에서 “ultimate business car”라는 키워드를 검색하게 되면 위 그림5 처럼 나오게 됩니다 (현재는 이 마케팅 전략이 유명해져서 다른 이미지들이 많이 나옵니다) . 이러한 검색엔진최적화(SEO) 적용 사례인 폭스바겐은 흔한 SEO의 사례로 쓰이고 있으며 발상의 전환을 하게 했던 사례입니다. 하지만 이렇게 키워드의 순서를 1~5위까지 맞추는 것은 정말 많은 노력이 필요했을 것 같습니다.
마치며
검색엔진 최적화 작업은 사이트(네이버, 구글 등)마다 기준이 조금씩 다르게 설정되어 있습니다. 그러므로 최적화 작업 전에 원하는 사이트를 선정하고 그 사이트의 기준에 맞게 최적화 작업을 해주는 것이 중요합니다.
네이버 및 구글 가이드는 아래 링크를 참조하시면 됩니다.
위에 서술된 적용법의 내용을 좀 더 상세하게 보실 수 있으며 각 사이트 마다의 다른 기준의 가이드가 명시되어 있습니다. 한곳의 사이트에서 명시된 가이드가 다른 사이트에서는 제한이 되는 내용이 있으니 최적화 작업 전 꼭! 꼭! 가이드를 필독하시고 진행하시는걸 추천드립니다.
네이버 웹마스터도구 도움말 및 가이드
https://webmastertool.naver.com/guide/basic_optimize.naver#chapter3.1구글 검색엔진 최적화(SEO) 초보자 가이드
https://support.google.com/webmasters/answer/7451184?hl=ko&ref_topic=4564315
무조건 접속자의 수를 많이 올리는 것으로만 검색엔진 최적화를 이용하게 된다면 오히려 안 좋은 검색엔진에서 스팸으로 해석되어, 순위가 하락하거나 페널티를 받을 가능성이 있고 한번 방문한 방문자에게 나쁜 이미지를 심어 오히려 재방문을 하지 않거나 나쁜 이미지로 인식되어 악영향이 갈 수 있습니다. 그러므로 검색엔진 알고리즘이 지속해서 업데이트하며 SEO를 단순한 방문자 유입을 확대하기 위한 목적으로만 사용하기보다 사용자에게 유익한 정보를 제공하면서도 그 자체가 검색엔진 가이드의 최적화가 되어 일거양득의 효과를 노리기 위해 콘텐츠 마케팅을 도입하는 것이 좋을 것입니다.
검색엔진 최적화 작업은 이제는 웹사이트 제작 시 필수적인 요소로 변해 가고 있습니다. 포털사이트에서 검색 화면에서 경쟁 회사보다 상위 링크에 위치하는 것이 방문자의 유입을 늘려서 회사 또는 상품을 홍보할 수 있는 최고의 마케팅 방법이기 때문입니다. 매번 돈을 들여 광고하는 것보다 제대로 된 최적화 작업으로 지속적인 효과를 얻을 수 있길 바랍니다. 또한, 검색엔진 알고리즘의 정확도는 꾸준히 향상되고 있으며 스팸 및 부당한 코드 대한 필터링이 점점 정밀해지고 있습니다. 따라서 지속적인 검색엔진의 가이드 확인 및 변경이 필요할 것입니다.
참고문헌검색엔진최적화 A to Z (2012).저자 제니퍼 그라포네, 그라디바 쿠진
구글 Search Console(https://support.google.com/webmasters)
네이버 웹마스터도구 https://webmastertool.naver.com/)
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/300





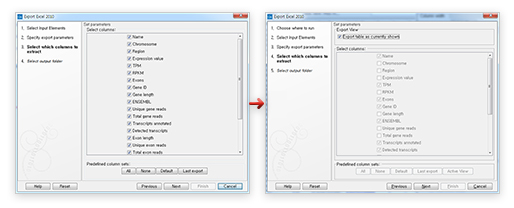
 [그림 10] QIAseq 분석에 찰떡인 QIAGEN Sets 다운로드
[그림 10] QIAseq 분석에 찰떡인 QIAGEN Sets 다운로드