
인공지능(AI)의 역사
- Posted at 2020/03/10 14:16
- Filed under 지식관리

인공지능(Artificial Intelligence)의 역사에 대해 알아볼까 합니다.




인공지능이 우리에게 확 다가온 계기가 있었습니다. 바로 2016년 알파고와 이세돌 9단의 바둑 대국이었죠. 당연히 인간이 승리하리라 생각했던 예상과는 다르게 알파고가 이세돌 9단을 4:1이라는 압도적인 스코어로 승리하면서 인공지능에 대한 전 세계적인 관심이 쏟아졌고, 그 이후로 알파고 뿐만 아니라 인공지능 산업이 빠른 속도로 성장하고 있습니다.
인공지능 산업의 성장으로 “AI와 딥 러닝을 활용한 저해상도 의료영상을 고해상도로 변환”이나 “국내 최초 강화학습 AI 알고리즘을 적용한 머신러닝 적용” 등과 같은 기사들을 많이 볼 수 있습니다. 이러한 기사들에서 인공지능이라는 용어와 함께 사용되는 딥 러닝, 머신러닝은 무엇일까요? 인공지능의 역사를 알아보기에 앞서 간략하게 인공지능, 머신러닝, 딥 러닝에 대한 개념을 한 번 알아보겠습니다.
[출처] 투비소프트 칼럼
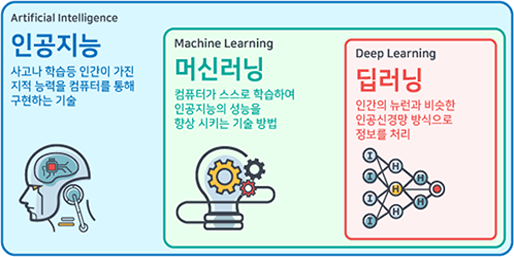
인공지능의 정의는 ‘사고나 학습 등 인간이 가진 지적 능력을 컴퓨터를 통해 구현하는 기술’로서 개념적인 정의에 가깝습니다. 1950년대 인공지능을 연구하던 학자들이 인간의 지능과 유사한 특성을 가진 복잡한 컴퓨터 제작을 목표로 함께 연구를 시작했고, 이때 인공지능이라는 개념이 등장했습니다.
이러한 인공지능을 구현하기 위한 구체적인 접근 방식이 바로 머신러닝인 거죠. 머신러닝의 정의는 말 그대로 ‘컴퓨터가 스스로 학습하여 인공지능의 성능을 향상하는 기술 방법’을 의미합니다. 여기서 중요한 단어가 ‘스스로 학습’입니다. 프로그래머가 구체적으로 로직을 직접 코딩하는 것이 아닌, 빅데이터와 알고리즘을 통해 컴퓨터에 ‘학습’을 시켜 원하는 결괏값을 도출해내는 것이죠.
딥러닝이란 머신러닝의 한 분야로 인공신경망(Artificial Neural Network) 방식으로 정보를 처리하는 기술을 의미합니다. 최근 인공지능 붐을 일으킨 분야로 완전한 머신러닝을 실현하는 기술이라고 볼 수 있습니다.
요약하자면 그림에서 표시된 것과 같이 인공지능이 가장 큰 범주이고, 그다음으로 머신러닝, 가장 세부적인 부분이 현재의 인공지능 붐을 주도하고 있는 딥 러닝입니다. 이 세 단어의 관계를 정의하자면 다음과 같습니다.
-> 인공지능 ⊃ 머신러닝(기계 학습) ⊃ 딥 러닝(심층 학습)
인공지능의 역사000
초기 인공지능에 대한 연구는 인공지능이라는 개념이 없는 이론적인 분야였기에 다양한 분야의 수많은 학자가 연구했습니다. 일례로 인공지능이라는 용어는 1956년에 처음 등장하였지만, 현재 인공지능의 세부적인 부분으로 분류되는 딥 러닝의 기원이 되는 인공신경망에 대한 기초이론은 1943년도에 논문으로 발표되었습니다. 수많은 시행착오를 거치면서 인공지능이라는 학문의 분야가 생겨났고, 긴 시간 동안 정립된 이론과 기술들이 정리되어 현재의 인공지능 분야를 이루게 되었습니다. 본 글에서는 인간 두뇌의 뉴런 작용을 처음으로 논리적 모델로 설명한 1943년부터 시작됩니다.
1943, 딥러닝의 기원을 열다, 워런 맥컬럭 & 월터 피츠

1943년 논리학자인 월터 피츠(Walter Pitts)와 신경외과의 워렌 맥컬럭 (Warren Mc Cullonch)은 ‘A Logical Calculus of Ideas Immanent in Nervous Activity’ 논문을 발표합니다.
이 논문에서 뉴런의 작용을 0과 1로 이루어지는 2진법 논리 모델로 설명했고 이는 인간 두뇌에 관한 최초의 논리적 모델이었습니다. 이렇게 현재 인공지능의 트렌드를 이끌고 있는 딥 러닝에 대한 연구가 시작되었습니다.
1943, 딥러닝의 기원을 열다, 워런 맥컬럭 & 월터 피츠

[출처] 인공지능 그리고 머신러닝의 모든것, 고지식-거니
1950년 영국 수학자 앨런 튜링(Alan Mathison Turing)은 ‘계산 기계와 지능(Computing Machinery and Intelligence)’라는 논문을 발표합니다. 이 논문에서 앨런 튜링은 기계가 생각할 수 있는지 테스트하는 방법과 지능적 기계의 개발 가능성, 학습하는 기계 등에 관해 기술하였습니다. 이 기술을 현실화한 튜링머신은 존 폰 노이만 교수에게 직접 또는 간접적인 영향을 주어 현대 컴퓨터 구조의 표준이 되었습니다.
이후 1956년 인공지능이라는 용어가 처음으로 등장하였습니다. 1956년 미국 다트머스 대학에 있던 존 매카시(John McCarthy) 교수가 ‘다트머스 AI 컨퍼런스’를 개최하면서 초청장 문구에 ‘AI’라는 용어를 처음으로 사용했습니다.
We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire.
(1956년 여름 뉴 햄프셔 하노버에 있는 다트머스대에서 두 달 동안 10명의 과학자가 모여 인공지능을 연구할 것을 제안합니다)
이 AI 컨퍼런스에서 모인 10여 명의 과학자들은 앨런 튜링의 ‘생각하는 기계’를 구체화하고 논리와 형식을 갖춘 시스템으로 이행시키는 방안을 논의했습니다.
1950, Perceptron의 등장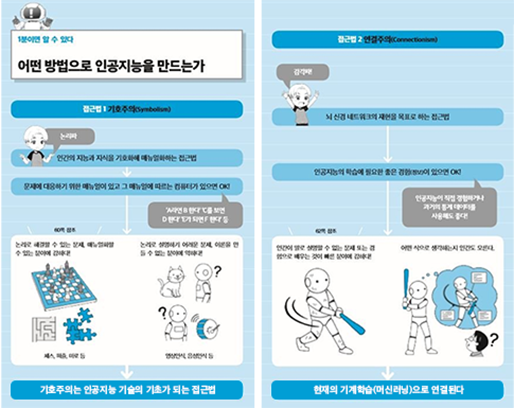
1950년대의 인공지능 연구는 크게 두 가지 분야로 구분되었습니다. 바로 '기호주의'와 '연결주의'인데요, 기호주의(Symbolism)은 인간의 지능과 지식을 기호화해 매뉴얼화하는 접근법이었고, 연결주의(Connectionism)는 1943년 월터 피츠와 워런 맥컬럭이 연구한 뇌 신경 네트워크의 재현을 목표로 하는 접근법이었습니다. 각 장단점이 있었으나 1950년대에 현실적으로 실현 가능한 기호주의 분야가 사람들의 관심을 더 받고 있었습니다.
1958년 기호주의로 독주하고 있던 마빈 민스키(Marvin Lee Minsky)에게 도전장을 내민이가 있었으니, 바로 퍼셉트론(Perceptron)을 고안한 마빈 민스키의 1년 후배인 프랭클린 로젠 블랫(Frank Rosenblatt)입니다. 퍼셉트론은 인공신경망(딥러닝)의 기본이 되는 알고리즘으로 월터 피츠와 워런 맥컬럭의 뇌 모델과 1949년에 발표된 도널드 헵(Donald Hebb)의 ‘헵의 학습이론’에 힌트를 얻어 가중치를 추가한 업그레이드 버전이었죠. 이렇게 세상 밖으로 나온 퍼셉트론은 사람들의 사진을 대상으로 남자와 여자를 구별해내고 뉴욕 타임즈에 실리게 됩니다. 인공지능 연구의 트렌드가 기호주의에서 연결주의로 넘어오게 되는 계기가 되었죠.
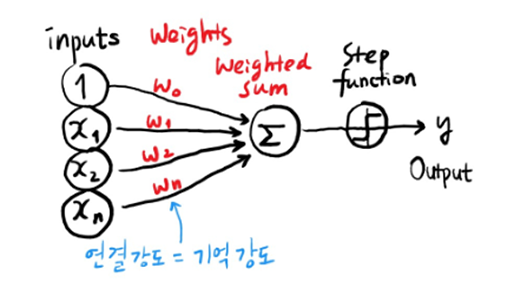
[출처] 인공지능 탄생의 뒷이야기, 야만ooo
1969, AI의 1차 겨울 : XOR 문제 등판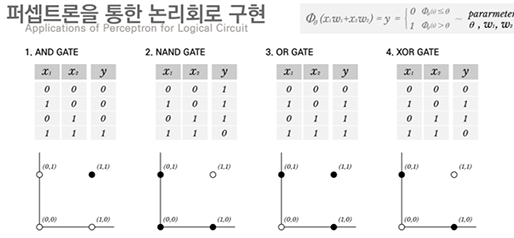
로젠 블랫의 퍼셉트론에 모든 관심이 집중되자 기호주의의 마빈 민스키는 제자 시모어 페퍼트(Seymour Papert)와 퍼셉트론의 한계를 수학적으로 증명하면서 로젠 블랫의 퍼셉트론이 무너지고 2년 뒤인 1971년 로젠 블랫이 사망하면서 인공지능의 빙하기가 도래하게 됩니다.
로젠 블랫의 퍼셉트론으로 AND, OR, NAND 같은 선형문제는 풀 수 있지만, XOR 같은 비선형 문제는 해결할 수 없었고, 대부분 데이터는 선형보다 비선형 형식으로 데이터가 분포되어 있었습니다. 이러한 문제로 퍼셉트론을 기반으로 한 수많은 인공지능 연구가 끊기게 되고 다시 마빈 민스키의 기호주의 학문으로 관심이 집중되었으나, 기호주의도 한계에 도달하면서 인공지능은 세간의 관심에서 점점 멀어져 갔습니다.
1986, AI의 부활 : 딥 러닝의 아버지 제프리 힌튼
[출처] Neural Network, Sliude Share
인공지능에 대한 관심은 줄어들었지만, 묵묵히 연구를 지속해오던 연구자들도 있었습니다. 1986년 인공지능의 첫 번째 빙하기를 깨고 인공지능의 부활을 알린 사람이 있었으니 바로 딥 러닝의 아버지라 불리는 제프리 힌튼(Geoffrey Everest Hinton)입니다. 제프리 힌튼 교수는 다층 퍼셉트론(Multi-Layer Perceptrons, MLP)과 Back-propagation Algorithm을 실험적으로 증명하였고 이를 통해 XOR 문제를 해결하였습니다.
사실 제프리 힌튼이 다층 퍼셉트론와 Back-propagation Algorithm을 고안해낸 것은 아니었습니다. 1969년 위치 호(Yu-Chi Ho)와 브라이손(Arthur E. Bryson)에 의해 Back-propagation Algorithm이 고안되었으며, 1974년 하버드대의 폴 워보스(Paul Werbos)는 다층 퍼셉트론 환경에서 학습을 가능하게 하는 Back-propagation Algorithm으로 박사학위 논문을 썼으나 인공지능 분야의 침체한 분위기 속에 8년 후 1982년에 논문을 발표하였습니다. 이것이 1984년 얀 르쿤(Yann LeCun)에 의해 다시 세상 밖으로 나왔고, 1986년 데이빗 럼멜하트(David Rumelhart)와 제프리 힌튼에 의해 세상에 알려지게 되었습니다.
1990년대 후반, AI 2차 겨울 : MLP의 문제점
제프리 힌튼의 다층 퍼셉트론과 Back-propagation Algorithm을 계기로 1990년대 초반까지 인공지능 연구에 큰 발전을 이루었습니다. 그러나 1990년대 다층 퍼셉트론에서도 한계가 보이기 시작하면서 인공지능 연구의 두 번째 빙하기를 맞이하게 됩니다.
두 번째 문제는 Vanishing Gradient와 Overfitting 이었습니다. 다층 신경망의 은닉층(Hidden layer)을 늘려야 복잡한 문제가 해결 가능한데 신경망의 깊이가 깊어질수록 오히려 기울기(gradient)가 사라져 학습이 되지 않는 문제인 Vanishing Gradient가 발생했습니다. 또한, 신경망이 깊어질수록 너무 정교한 패턴을 감지하게 되어 훈련 데이터 외 새로운 데이터에 대해서는 정확성이 떨어지는 Overfitting 문제가 발생했던 거죠.
2006, 제프리 힌튼의 심폐소생술 : 딥 러닝 용어의 등장
모두가 인공신경망을 외면하던 암흑기 시절에도 제프리 힌튼은 꿋꿋하게 인공신경망을 연구해왔습니다. 제프리 힌튼은 “A fast learning algorithm for deep belief nets” 논문을 통해 가중치(weight)의 초깃값을 제대로 설정한다면 깊은 신경망을 통한 학습이 가능하다는 것을 밝혀냈습니다.
기존 인공신경망과 크게 달라진 점은 없었지만, 인공지능의 두 번째 겨울을 거치면서 인공신경망이라는 단어가 들어간 논문은 제목만 보고 거절당하거나 사람들의 관심을 끌지 못해 deep을 붙인 DNN(Deep Neural Network)이라는 용어를 사용하면서 본격적으로 딥 러닝(Deep Learning) 용어가 사용되기 시작했습니다.
2012, ImageNet : ILSVRC
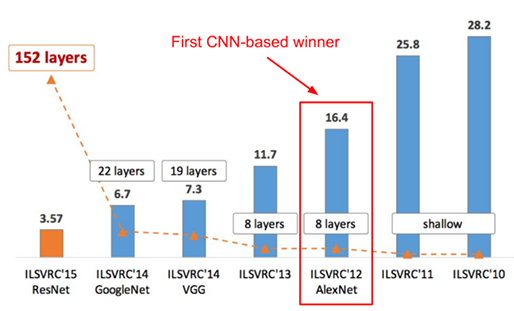
ImageNet는 2009년 페이페이 리(Fei-Fei Li)가 만든 방대한 이미지의 데이터베이스입니다. 인공지능을 학습시키기 위해서는 수천, 수만 번의 반복 학습이 필요한데 이때 알고리즘 뿐만 아니라 학습량도 매우 중요하다고 생각했죠. 이를 계기로 ImageNet이라는 방대한 이미지 데이터베이스를 구축하게 되었고, 2010년부터 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)라는 이미지 인식(image recognition) 경진대회도 진행하였습니다.
ILSVRC는 주어진 대용량의 이미지 셋을 데이터로 이미지 인식 알고리즘의 정확도, 속도 등의 성능을 평가하는 대회입니다. 2010년, 2011년까지는 얕은 구조(shallow architecture)를 가진 알고리즘이 우승하였으나, 약 26% 정도의 오류율을 보여 왔습니다. 오류율이 0.1%라도 낮아진다면 우승이라는 말이 있었을 만큼 얕은 구조 기반의 알고리즘으로는 오류율을 낮추는 것이 매우 힘든 일이었죠.
- https://blogs.nvidia.co.kr/2016/08/03/difference_ai_learning_machinelearning/
- https://m.blog.naver.com/qbxlvnf11/221296949593
- http://yangjaehub.com/newsinfo/학생기자단/?mod=document&uid=39
- https://brunch.co.kr/@storypop/28
- https://brunch.co.kr/@hvnpoet/80
- https://insilicogen.com/blog/owner/entry/edit/인공지능%20그리고%20머신러닝의%20모든것,%20고지식-거니
- https://www.youtube.com/watch?v=cNxadbrN_aI&feature=youtu.be
- https://www.youtube.com/watch?v=xMRKQBbHOzA&list=PL6ip5tgLI7PcStXTz8CRMhNWmT8M0dAWO&index=2
- https://insilicogen.com/blog/owner/entry/edit/퍼셉트론(Perceptron)%20-3%20(인공지능의%201차%20겨울)
- https://bskyvision.com/425
- https://www.itfind.or.kr/WZIN/jugidong/1888/file6111801471006205940-188802.pdf
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/340
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

