[Quipu Issue Paper] Genome Annotation Ⅶ - Professional Curation
- Posted at 2010/03/26 09:59
- Filed under 생물정보
연재 순서
1. Assembly
2. Variation study
3. Expression study
4. Epigenomics
5. Genome Annotation
6. Next Generation Bioinformatics
7. Data Management for web 2.0 Era
8. Semantic Network for Integrated Biology Data
9. Gene Network Discovery by Text-mining
10. Centralization for High-throughput Data Analysis
이번 연재는 Genome Annotation의 마지막 내용으로 수학적 알고리즘에 의한 유전자 예측으로 생각할 수 없었던 예외적인 부분을 실제 유전자의 구조를 하나씩 살펴가며 수정 작업을 거치는 Professional Curation에 대해 알아보겠습니다.
2-4-3. Professional Curation
A. 상동성 기반의 Annotation 수정
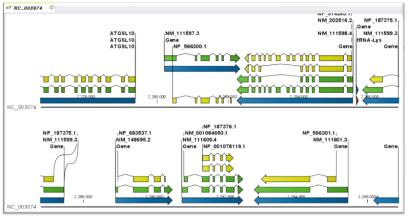
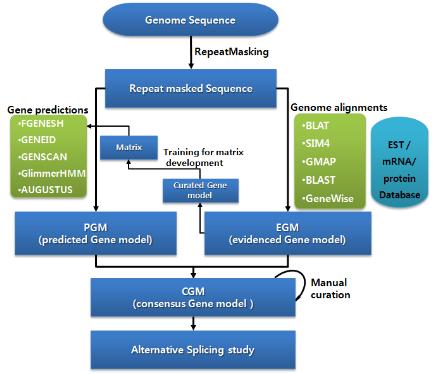
수학적 알고리즘에 의한 유전자 예측으로 생각할 수 없었던 예외적인 사항이 많이 발생한다. 따라서 이러한 부분은 실제 유전자의 구조를 하나씩 살펴가며 수정 작업을 거쳐 최종적인 유전체 분석을 수행하게 된다. 분석 가능한 소프트웨어로는 Apollo[2] 와 Pedant-Pro가 있다. Apollo는 오픈 소스로 제공되며, Berkeley Drosophila Project 수행을 위해 Sanger Institute에서 개발하였다.
유전자의 구조 정보를 편집하기 위한 프로그램으로 evidence 데이터의 alignment 정보와 structural annotation 결과 형성된 Consensus Gene Model 정보를 같이 보며 수정 작업을 수행 한다(그림 12).
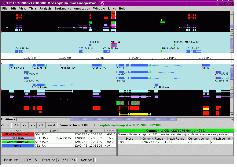
입력 포맷으로 GFF3, Ensemble, XML 형식이 가능하며 Chado 데이터베이스로부터 직접 데이터를 읽어 들일수도 있다. 또한 삽입(Insertion), 삭제(Deletion), 확장(Extension), 분리(Split), 결합(Merge), 이동 그리고 변환(Replacement) 등 가능한 모든 유연한 편집 모드를 이용하여 유전자의 구조 정보를 편집할 수 있다. 또한 편집 시 필요한 주석 태그를 덧붙일 수 있는 것 또한 장점이라 할 수 있다.
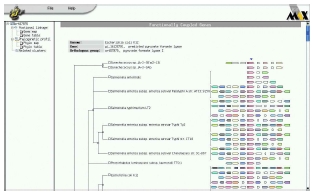
B. 기능 분석 결과의 수정(functional annotation)
서열 상동성 및 도메인 정보를 통해 분석되어진 유전자의 기능 정보에서 전문가의 분석에 의존하여 알고리즘에 의한 오류를 수정하거나 분석 정보를 편집, 수정할 수 있다. 이전 페이지에서 언급한 Pedant-Pro에서는 이와 같은 전문가의 수정 기능과 수정된 정보의 업데이트 기능을 지원하고 있어서 최종적으로 가장 정확한 유전체 분석 정보를 얻을 수 있다(그림 13). 수치상 상동성이 높은 단백질로 유전자 매핑이 이루어져야 하므로 발현 정보, 도메인 정보 등을 종합하여 단백질의 기능을 수정해야 할 때 이용하게 된다. 이러한 작업은 대부분 생물학적 지식을 갖춘 다수의 전문가들에 의해 진행되게 된다. 따라서 전문가에 의한 기능 분석 수정에 대한 이력 정보를 관리하는 것 또한 중요하다고 할 수 있다.
다음주 연재에서는 NGS Application의 마지막 내용으로 Next Generation Sequencing 데이터를 분석하고 처리하는 Bioinformatics Knowledge Management에 대해 알아보겠습니다. 많은 관심 부탁드립니다.
참고문헌
1. Lowe, T.M. and Eddy, S.R. (1997) tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 25, 955-964.
2. Lewis SE, et al. (2002). Apollo: a sequence annotation editor. Genome Biology. 12, research0082
3. Noh SJ, Lee K, Paik H, Hur CG. (2006) TISA: tissue-specific alternative splicing in human and mouse genes. DNA Res. 13, 229-243
4. Stanke M, Schoffmann O, Morgenstern B, Waack S. (2006) Gene prediction in eukaryotes with a generalized hidden Markov model that uses hints from external
sources. BMC Bioinformatics. 7, 62.
5. Burge, C. and Karlin, S. (1997) Prediction of complete gene structures in human genomic DNA. J. Mol. Biol. 268, 78-94.
6. Salamov AA, Solovyev VV. (2000) Ab initio gene finding in Drosophila genomic DNA. Genome Res. 10, 516–522.
7. Majoros, W.H., Pertea, M., and Salzberg, S.L. TigrScan and GlimmerHMM: two open-source ab initio eukaryotic gene-finders Bioinformatics 20, 2878-2879.
8. G. Parra, E. Blanco, and R. Guigó, (2000) Geneid in Drosophila Genome Research 4, 511-515.
9. Haas BJ, Salzberg SL, Zhu W, Pertea M, Allen JE, Orvis J, White O, Buell CR, Wortman JR. (2008) Automated eukaryotic gene structure annotation using
EVidenceModeler and the Program to Assemble Spliced Alignments. Genome Biology 9, R7
10. Korf I. (2004) Gene finding in novel genomes. BMC Bioinformatics. 5, 59.
11. Kan, Z., Rouchka, E.C., Gish, W., and States, D. 2001, Gene structure prediction and AS analysis using genomically aligned ESTs, Genome Res. 11, 889–900.
12. Eyras, E., Caccamo, M., Curwen, V., and Clamp, M. 2004, ESTGenes: AS from ESTs in Ensembl, Genome Res. 14, 976–987.
13. Kent, W.J. 2002, BLAT-The BLAST-Like Alignment Tool, Genome Res. 12, 565–664.
14. Florea, L., Hartzell, G., Zhang, Z., Rubin, G.M., Miller, W. 1998, Computer program for aligning a cDNA sequence with a genomic DNA sequence, Genome Res. 8,
967–974.
15. Huang X, Adams MD, Zhou H, Kerlavage AR. (1997) A tool for analyzing and annotating genomic sequences. Genomics. 46, 37–45.
16. Wu TD, Watanabe CK. (2005) GMAP: a genomic mapping and alignment program for mRNA and EST sequences. Bioinformatics. 21, 1859–1875.
17. Birney E, Clamp M, Durbin R. (2004) GeneWise and Genomewise. Genome Res. 14, 988–995.
Posted by 人Co
- Tag
- alignment, Apollo, Curation, Gene Model, Genome Annotation, GFF3, Iisilicogen, NGS, Pedant-Pro, Sanger Institute, 인실리코젠
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/63