
예제로 따라해보는 Jupyter, pandas 데이터 분석
- Posted at 2016/01/22 14:53
- Filed under 지식관리
Jupyter는 웹환경에서 실행코드와 문서를 함께 작성하면서 실행 결과 및 가시화 결과 (차트 등)을 확인할 수 있는 웹 어플리케이션 프로그래밍 도구입니다. 동작하는 코드와 그 결과를 문서와 함께 직접 만들고, 또 변경하며 관리할 수 있다는 장점때문에 데이터 분석 실무에 폭넓게 사용되고 있습니다. 당사 R&D Center와 컨설팅팀에서도 일부 생물정보 분석을 Jupyter Notebook으로 수행하고, 그 결과를 고객에게 제공하고, 직접 시연하면서 좋은 반응을 얻고 있습니다.
pandas는 효과적인 데이터분석을 지원하는 python 모듈입니다. R에서 자주 사용되는 DataFrame, 즉 엑셀 쉬트 같은 2차원 테이블 데이터를 파이썬에서도 좀더 파이썬스럽게 사용할 수 있습니다. 이전에는 데이터 분석한다 하면, R로만 해야하는 경우가 많았었는데, pandas가 등장한 뒤로, 파이썬에서도 손쉽게 DataFrame 데이터를 다루고, 프로그래밍할 수 있게 되었습니다. 데이터 분석분야에 R이 더 좋으냐, Python이 더 좋으냐 논란이 있기도 했습니다. (R vs Python for Data Science: The Winner is …) 각각 장단점이 있습니다만, 객체지향적이고, 성능 더 좋고, 응용프로그램을 만들기 좋다는 점 때문에 점점 Python을 활용한 데이터 분석이 점점 더 부각되고 있습니다. 특히, Jupyter 환경에서 pandas로 데이터 분석하고, 동작코드를 잘 문서화해두면, 기존의 어떤 데이터 분석 환경보다 더 나은 생산성을 기대할 수 있습니다.
본 블로그 포스팅을 통해, Jupyter와 pandas의 데이터 분석 사례를 쉬운 예제와 함께 소개해보고자 합니다. (Python, Jupyter, pandas는 모두 잘 설치되어 있다고 가정합니다. 설치 방법은 별도의 문서를 확인하세요)
이번에 소개할 데이터 분석 예제는 다음과 같은 성적표입니다.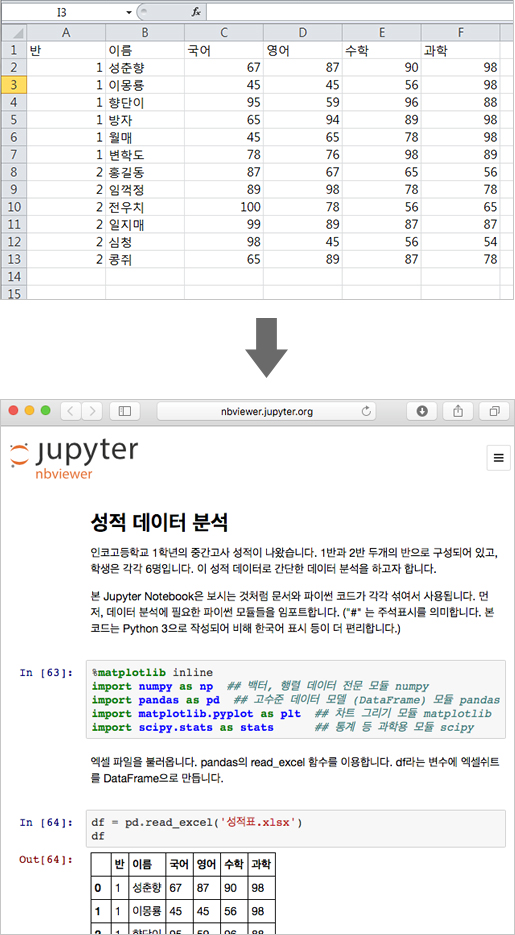
위 데이터를 갖고, 1반과 2반은 통계적으로 유의한 성적차이가 있는지, 유의한 차이를 나타내는 과목은 어떤 과목인지, 성적 패턴이 비슷한 학생은 누구인지 등등, 저 데이터를 이용해서 알 수 있는 정보들이 많습니다. 이를 Jupyter로 분석해 보겠습니다.
다음 링크를 클릭하면, Jupyter 문서를 볼 수 있습니다. --> 성적 데이터 분석 사례
Jupyter의 장점이 분석용 프로그램 코드가 함께 문서화된다는 것입니다. 링크의 설명을 참고하세요, (링크의 메뉴에 보면 json 파일 다운로드가 있습니다. json 파일과 아래 성적표.xlsx 파일을 하나의 디렉토리에 두고 Jupyter를 실행하시면, 본 문서 겸 프로그램을 직접 구동할 수 있습니다.)
 성적표.xlsx
성적표.xlsx.
잘 보셨나요? 이 예제는 간단한 성적표이지만, 실제 실무의 많은 데이터들이 이것과 비슷합니다. 생물정보 분석한다면 가로는 유전자 혹은 유전좌위, 세로는 샘플인 데이터를 많이 다루겠지요. 핵심 개념과 활용 방법은 비슷합니다. 모쪼록 이 자료가 데이터 분석 실무를 수행하는데 도움이 되길 바랍니다. 다음 기회에 또 다른 유용한 통계 분석기능을 소개하겠습니다.
작성자 : R&D센터 김형용 책임 개발자
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/197
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

